模型开发
模型训练
模型训练包括模型预训练和微调。预训练(Pretrain)是指在特定任务上进行微调之前,对大语言模型进行的初始训练,旨在通过处理大规模的语料库数据,让模型学习到语言的统计规律、语义信息和上下文关系,从而为后续的微调任务提供强大的语言理解和生成能力。微调包括有监督微调(SFT)和直接偏好优化(DPO),是提高模型性能的功能模块,是模型性能优化的重要一步,AI开发者可以通过构建特定任务的训练集,调整参数训练模型,训练模型学习业务数据和业务逻辑,以使其更好地适应特定的任务或应用场景,从而提高在特定任务中的模型性能。
有监督微调(SFT)即在预训练模型的基础上,利用带标签的数据进行进一步训练,以适应特定任务。通过这种方式,模型可以学习特定任务的知识,从而在该任务上表现得更好,显著提升模型的性能和准确性。
直接偏好优化(DPO)是一种基于用户偏好数据的优化方法,通常用于增强模型在生成任务上的表现。与SFT不同,DPO不依赖明确的标签数据,而是通过用户或系统的偏好数据来优化模型,能够显著提升模型的用户体验和满意度。
当前VastTrain 平台支持模型训练方法包括全量、LoRa、QLoRa。当模型训练类型为预训练时,训练方法仅支持全量;当模型训练类型为有监督微调时,训练方法支持全量、LoRa、QLoRa;当模型训练类型为直接偏好优化时,训练方法支持LoRa、QLoRa。
在模型预训练中,全量训练是指从头开始训练一个模型,使用随机初始化的参数,在特定任务或领域的数据集上完全重新训练模型;在微调训练中,全量训练是指在预训练模型的基础上,对所有参数进行微调,使模型适用特定任务。全量训练适用于数据和资源充足的高精度任务。
LoRA是一种低秩适应技术,通过引入低秩矩阵来调整模型权重,从而减少微调过程中需要更新的参数数量。这种方法可以显著降低微调的计算成本和存储需求。 LoRA训练适用于资源有限且需要快速迭代的任务
QLoRA是在LoRA的基础上引入量化技术,通过对模型参数进行量化处理,进一步减少计算和存储成本。QLoRA训练适用于资源极度受限的场景,进一步优化计算和存储成本。
登录至VastTrain,在“控制台”页面的左侧导航树选择“模型开发 > 模型训练”,进入“模型训练”页面,包含创建训练任务和训练任务列表。用户在该页面可创建训练任务、评估训练完成的模型、克隆训练任务、查看训练详细信息、停止或删除训练任务。模型训练页面如图 56所示。
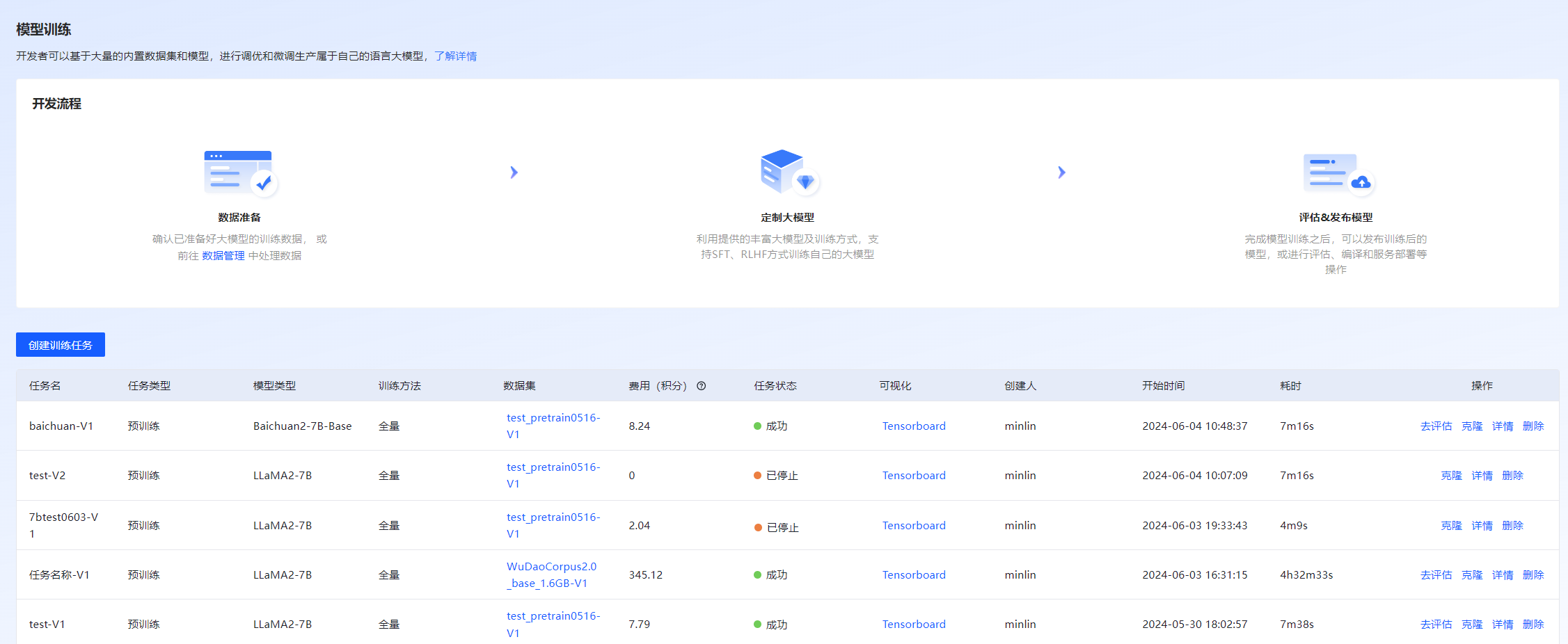
图 56 模型训练
创建训练任务
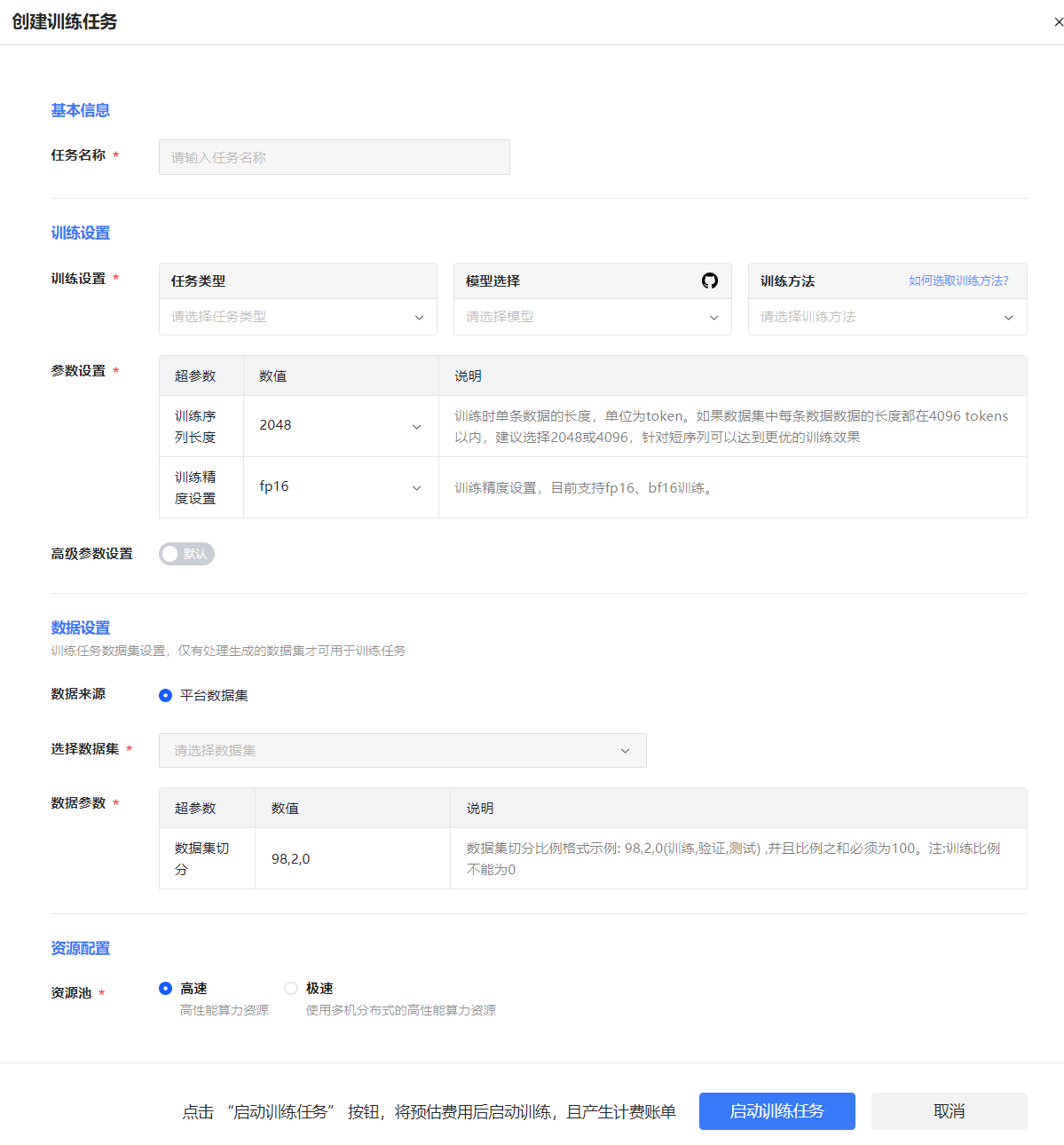
图 57 创建训练任务
参数 |
说明 |
|---|---|
基本信息 |
|
任务名称 |
设置训练任务名称。 |
训练设置 |
|
任务类型 |
训练任务类型,可设置为预训练(pretrain)、有监督训练(sft)或直接偏好优化(dpo)。 |
模型选择 |
待训练的模型。 |
训练方法 |
模型训练方法。
|
参数设置 |
|
训练序列长度 |
训练时单条数据的长度,单位为token。如果数据集中每条数据的长度都在4096 tokens以内,建议设置为2048或4096,以便可以达到更优的训练效果。 |
训练精度设置 |
设置模型训练精度。可设置为fp16、bf16。 |
高级参数设置 (默认关闭,详细说明参见下表) |
|
数据设置 |
|
数据来源 |
当前仅支持设置为平台数据集。 |
选择数据集 |
根据任务类型选择训练数据集。 |
数据参数 |
数据集切分:对数据集按比例进行切分。格式:98,2,0,表示数据集按98:2:0比例切分为训练集(98%)、验证集(2%)、测试集(0%)。其中,数据集切分比例之和必须为100,且训练比例不能设置为0。 |
资源配置 |
|
资源池 |
可设置为高速或极速。
|
如果训练方法为全量,高级参数界面如图 58,详细说明如表 11所示。
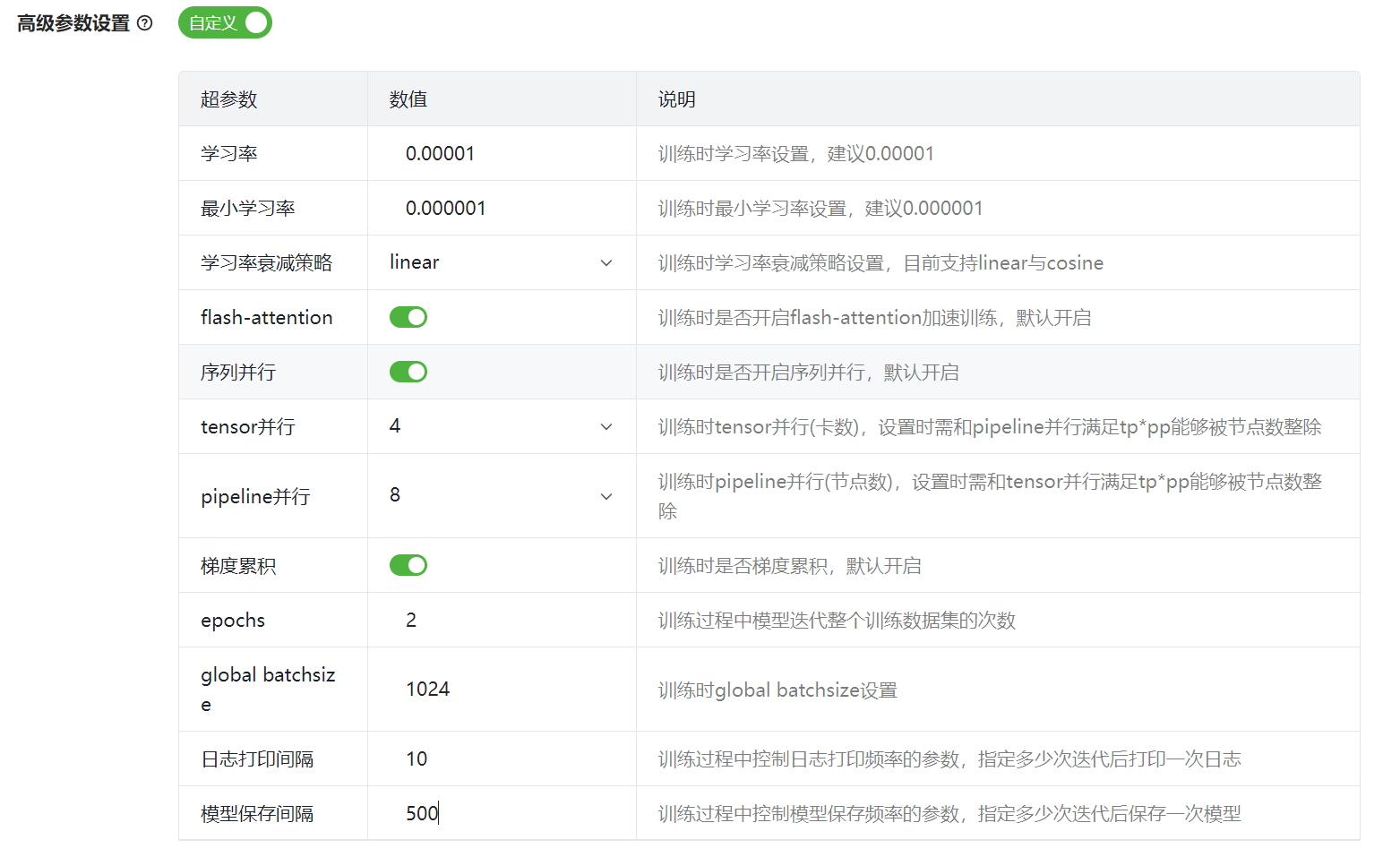
图 58 全量高级参数
参数 |
说明 |
|---|---|
学习率 |
设置训练时学习率。 |
最小学习率 |
设置训练时最小学习率。 |
学习率衰减策略 |
设置训练时学习率衰减策略,支持linear与cosine。 |
flash-attention |
训练时是否开启flash-attention加速训练。默认:开启。 |
micro batchsize |
设置训练Micro Batchsize。支持设置为 1 或 2。 |
序列并行 |
训练时是否开启序列并行。默认:开启。 |
tensor并行 |
设置训练时tensor并行数量。 |
pipeline并行 |
设置训练时pipeline并行数量。 |
梯度累计 |
训练时是否开启梯度累计。默认:开启。 |
epochs |
设置循环训练整个数据集的次数。 |
global batchsize |
设置训练Global Batchsize。 |
日志打印间隔 |
设置训练时日志打印间隔,即训练迭代指定的次数后打印一次日志。 |
模型保存间隔 |
设置训练时模型保存间隔,即训练迭代指定的次数后保存一次模型。 |
如果训练方法为 lora,高级参数界面如图 59,详细说明如表 12所示。
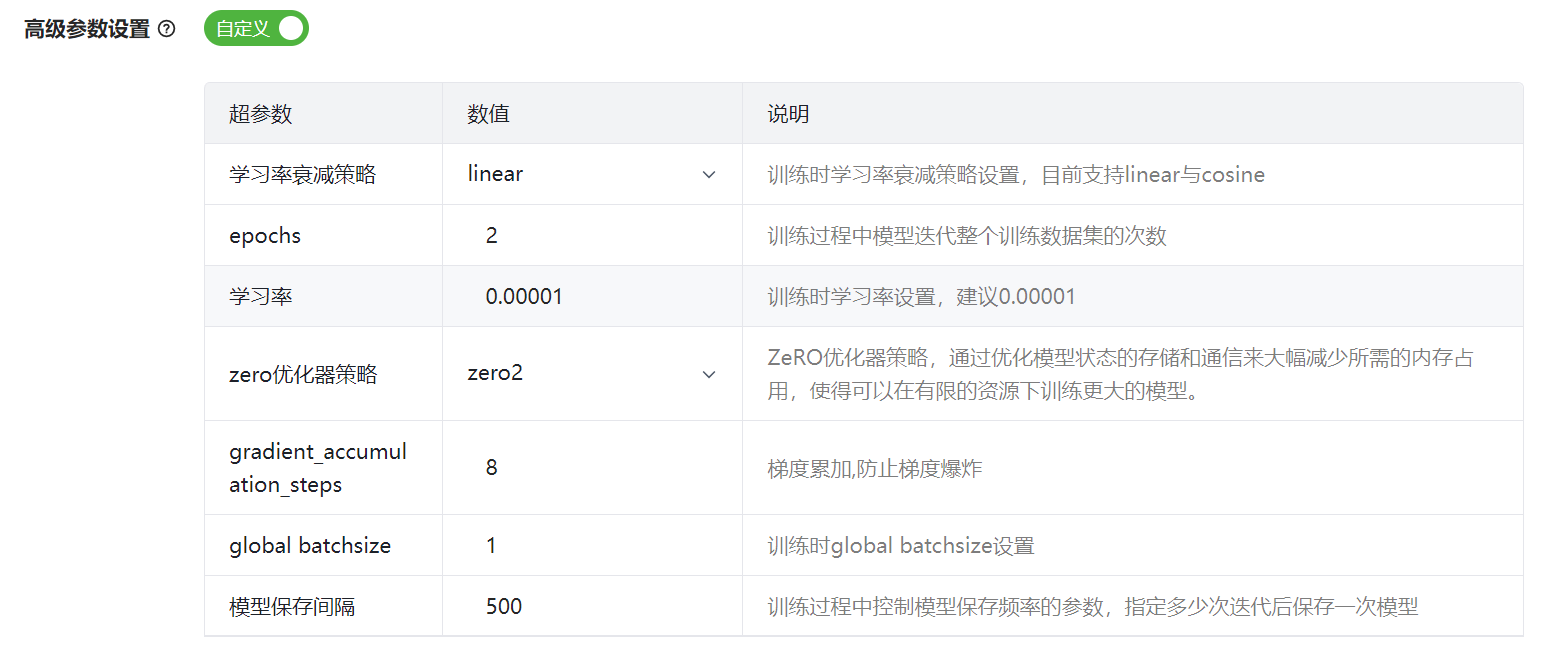
图 59 LoRa高级参数
参数 |
说明 |
|---|---|
学习率衰减策略 |
设置训练时学习率衰减策略,支持linear与cosine。 |
epochs |
设置循环训练整个数据集的次数。 |
学习率 |
设置训练时学习率。 |
zero优化器策略 |
ZeRO优化器策略,通过减少冗余,提高模型训练的内存效率,从而使得更大的模型可以在有限的硬件资源上进行训练。 当前仅支持“zero2” 。 |
gradient_accumulation_steps |
梯度累积步数。 |
global batchsize |
设置训练Global Batchsize。 |
模型保存间隔 |
设置训练时模型保存间隔,即训练迭代指定的次数后保存一次模型。 |
如果训练方法为 qlora,高级参数界面如图 60,详细说明如表 13所示。
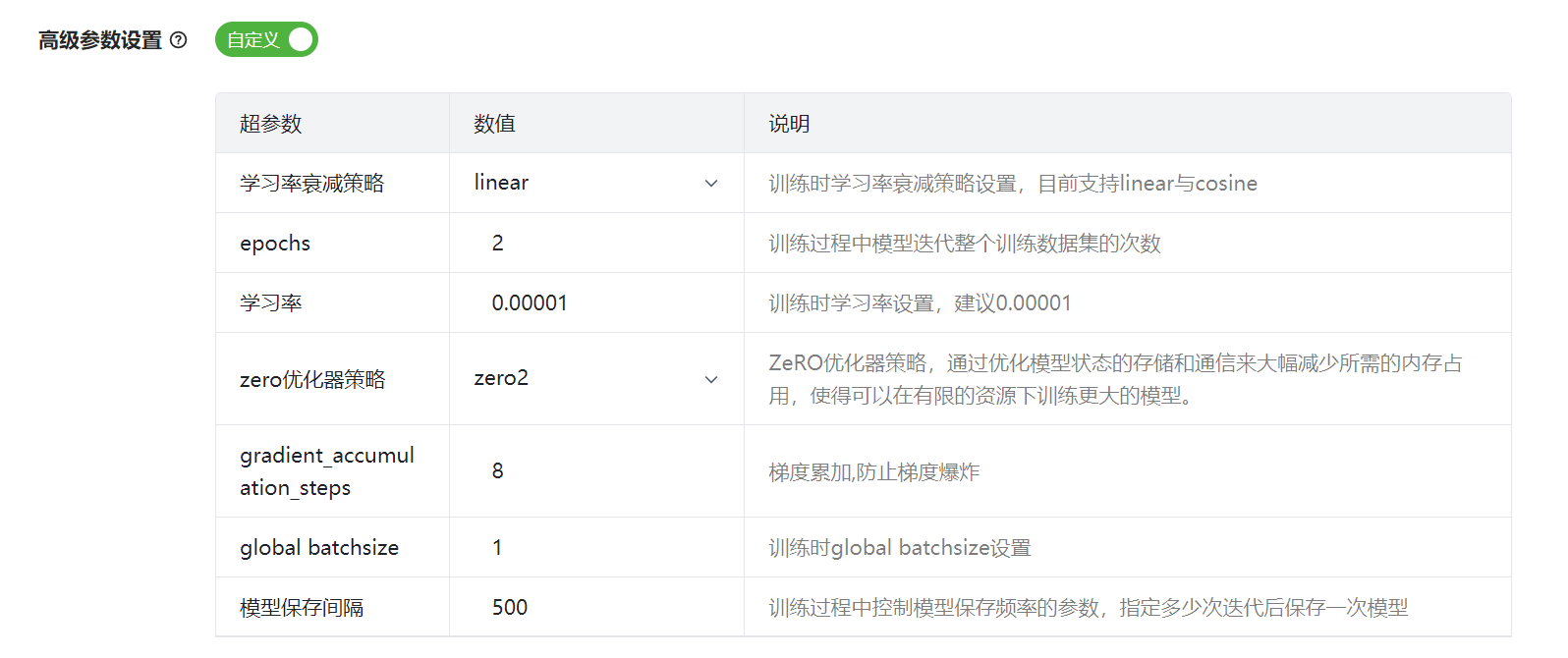
图 60 QLoRa高级参数
参数 |
说明 |
|---|---|
学习率衰减策略 |
设置训练时学习率衰减策略,支持linear与cosine。 |
epochs |
设置循环训练整个数据集的次数。 |
学习率 |
设置训练时学习率。 |
zero优化器策略 |
ZeRO优化器策略,通过减少冗余,提高模型训练的内存效率,从而使得更大的模型可以在有限的硬件资源上进行训练。 当前仅支持“zero2” 。 |
gradient_accumulation_steps |
梯度累积次数。 |
global batchsize |
设置训练Global Batchsize。 |
模型保存间隔 |
设置训练时模型保存间隔,即训练迭代指定的次数后保存一次模型。 |
启动训练任务后,VastTrain会根据训练时长进行扣费,详细可参考计费概述。
查看训练详情
在对应的训练任务栏单击“详情”,可查看如下信息。
在“训练参数”页签查看当前训练任务的训练类型、参数设置、训练的数据集等。

图 61 查看训练参数
在“进度”页签查看训练进度以及查看或下载不同阶段的日志信息等。
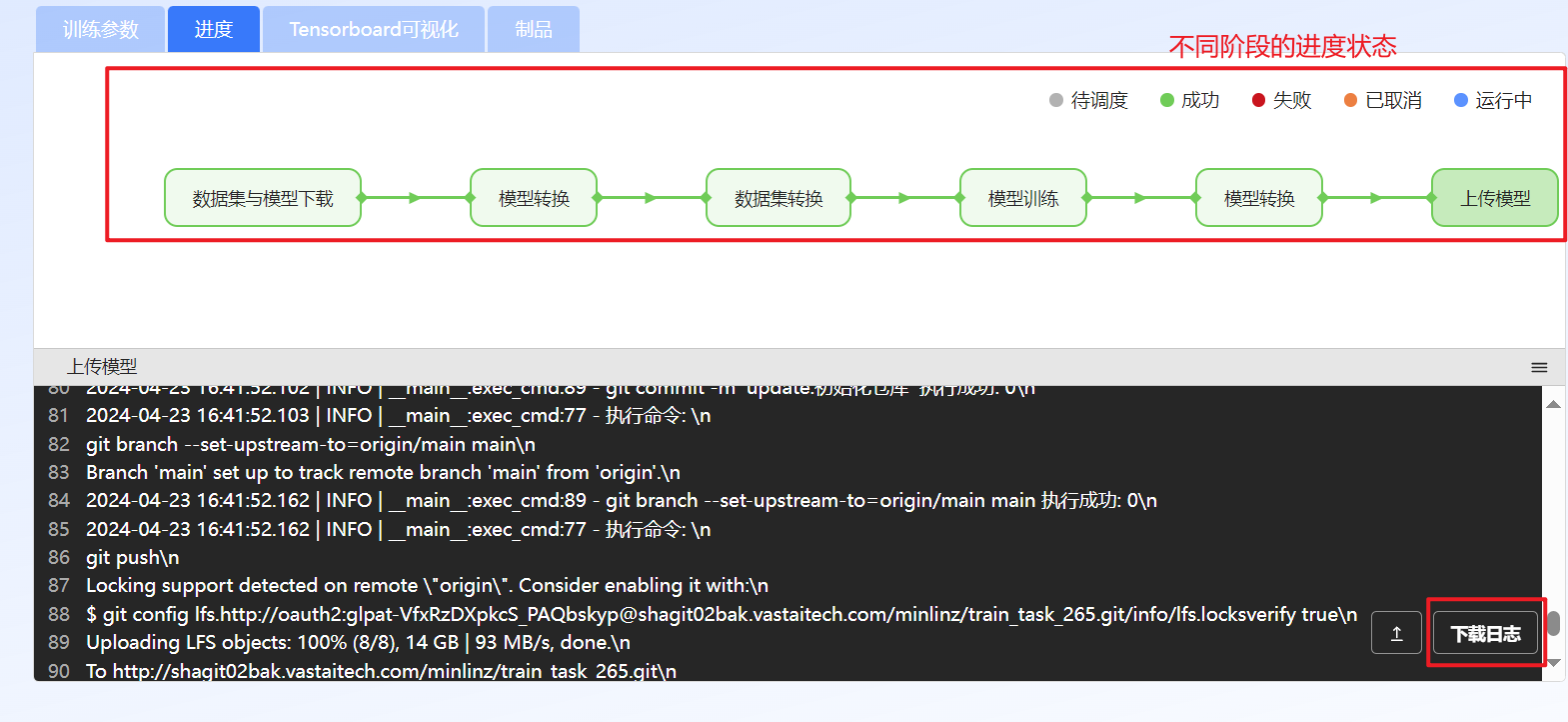
图 62 查看训练进度
在“Tensorboard可视化”页签查看训练过程中实时的参数变化。

图 63 训练过程可视化
在“制品”页签下载已训练完成的模型。
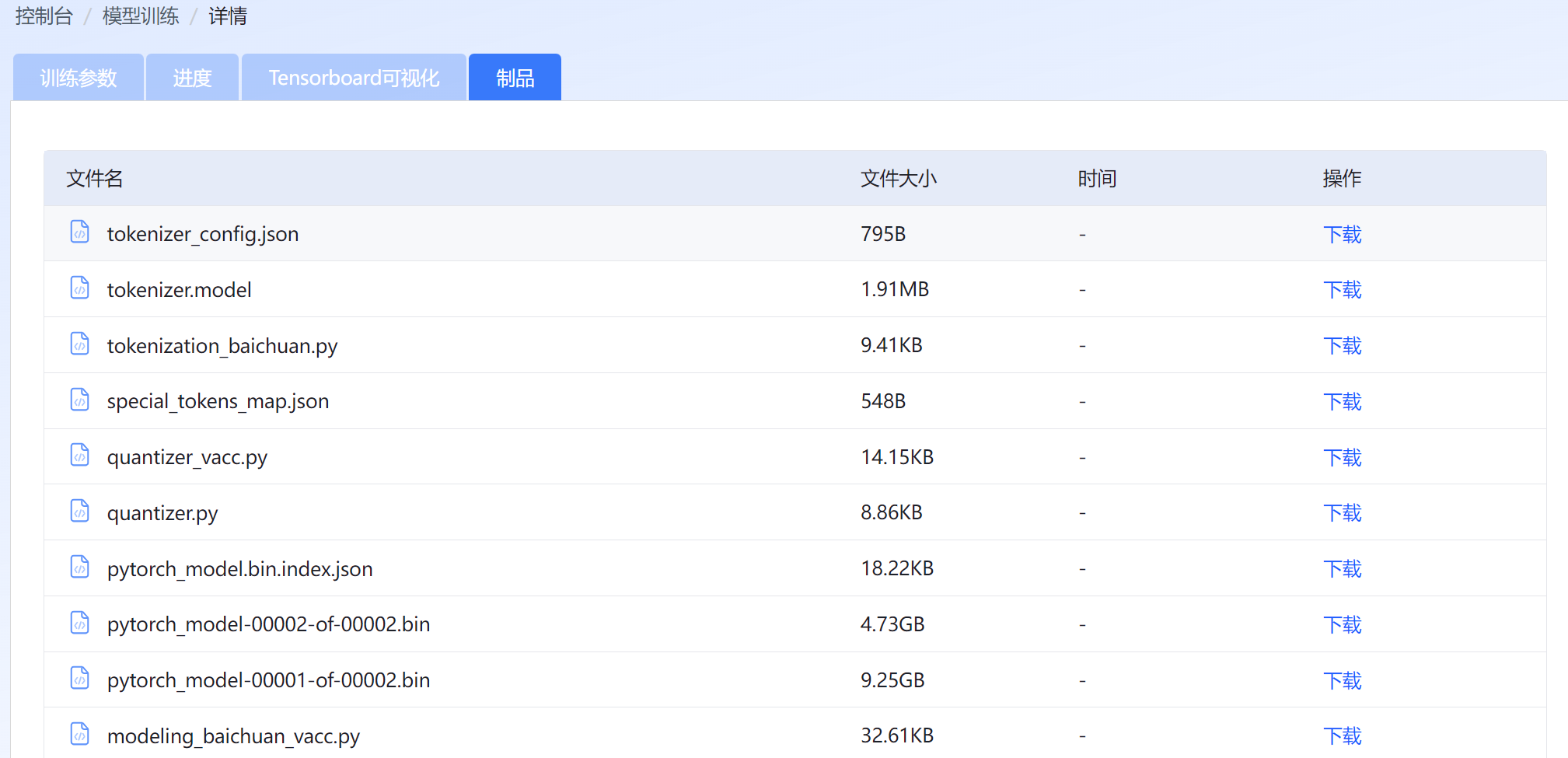
图 64 下载制品
模型评估
模型评估是大模型开发和应用中的关键环节,是对大模型的输出效果进行全方位的评价。模型评估当前仅支持文本类模型。
登录至VastTrain,在“控制台”页面的左侧导航树选择“模型开发 > 模型评估”,进入“模型评估”页面,包含创建评估任务和评估任务列表。用户在该页面可创建评估任务、对评估完成的模型进行量化编译、查看评估后的评分细则、查看评估详细信息、停止或删除评估任务。模型评估页面如图 65所示。
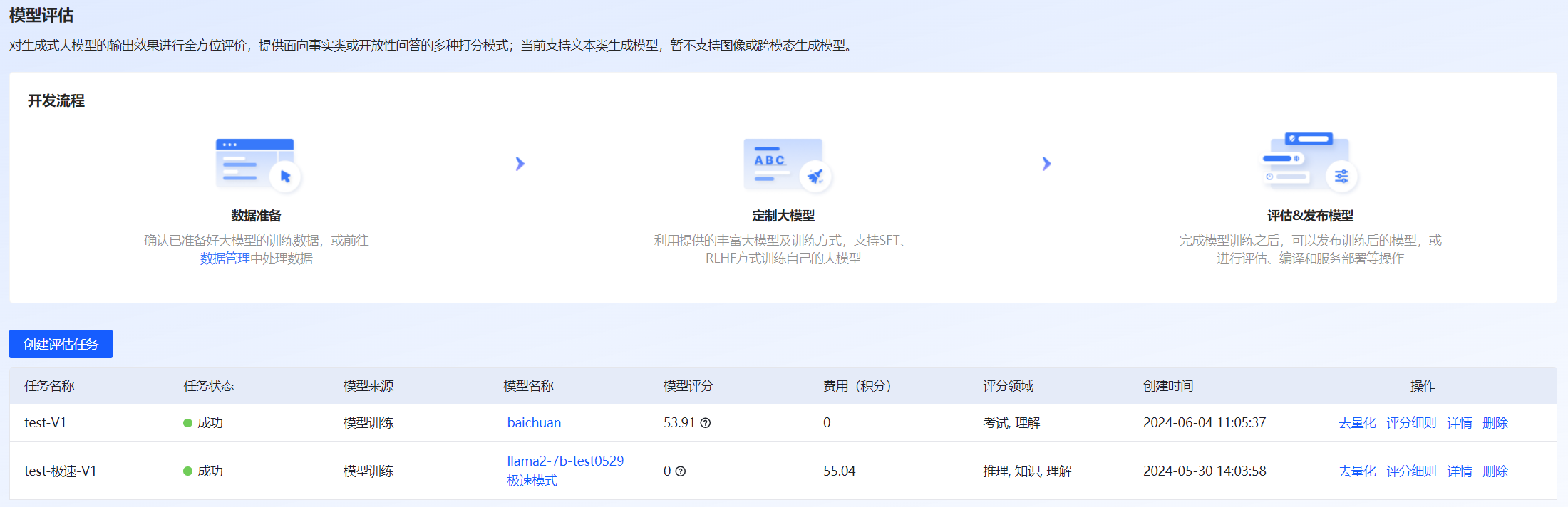
图 65 模型评估
创建评估任务
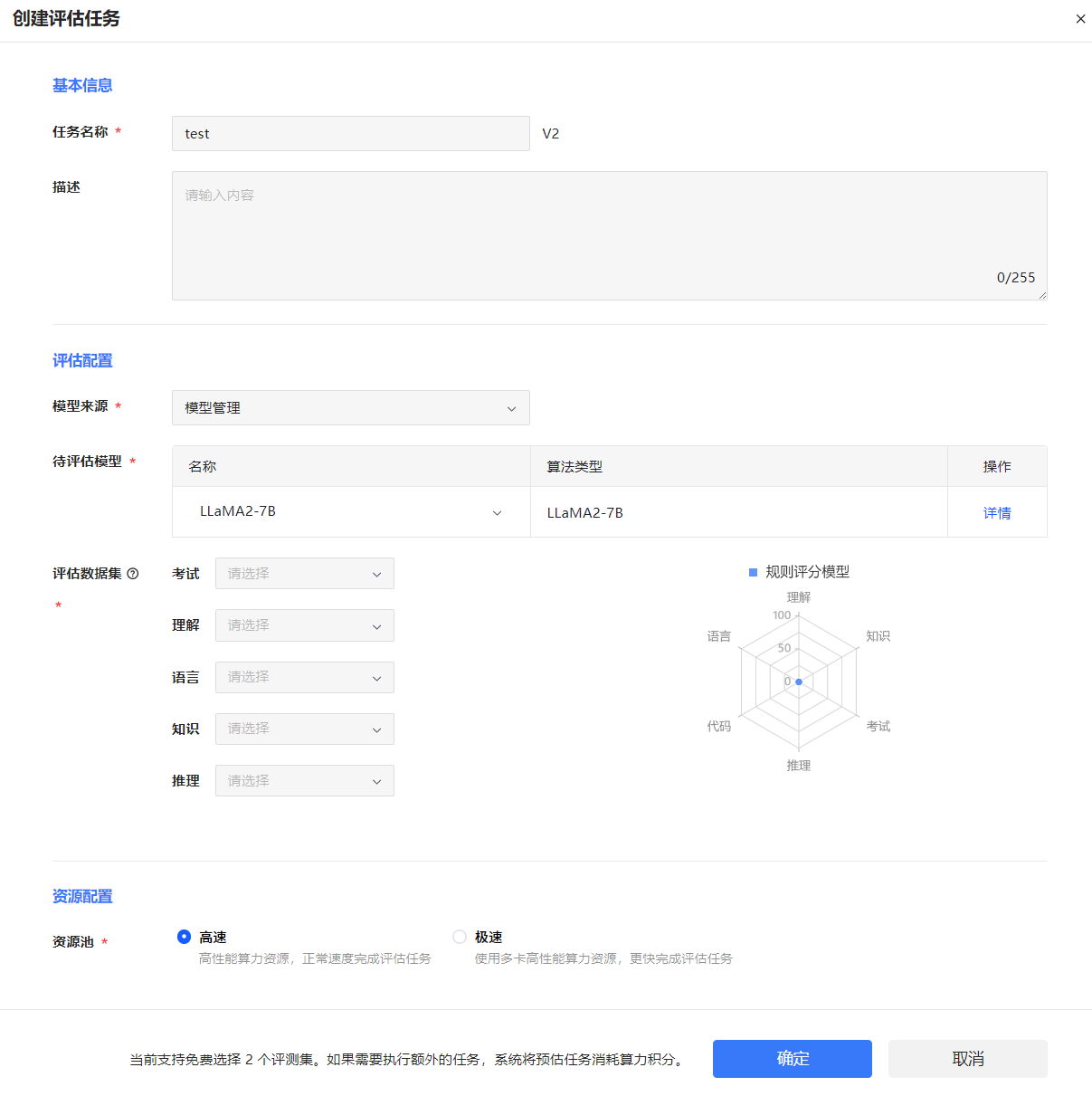
图 66 创建评估任务
参数 |
说明 |
|---|---|
基本信息 |
|
任务名称 |
设置评估任务名称。 |
描述 |
对评估任务进行简单描述。 |
评估配置 |
|
模型来源 |
选择模型来源。支持选择平台内置的模型和用户自己训练的模型。 |
待评估模型 |
选择待评估的模型。 |
评估数据集 |
选择评测数据集。如果选择的评测数据集超过两个,则平台将根据预估任务消耗算力积分。 |
资源配置 |
|
资源池 |
可设置为高速或极速。
|
查看评估详情
在对应的评估任务栏单击“详情”,可查看如下信息。
在“评估参数”页签查看当前评估任务的评估模型、评测数据集详情等。

图 67 查看评估参数
在“进度”页签查看评估进度以及查看或下载不同阶段的日志信息等。
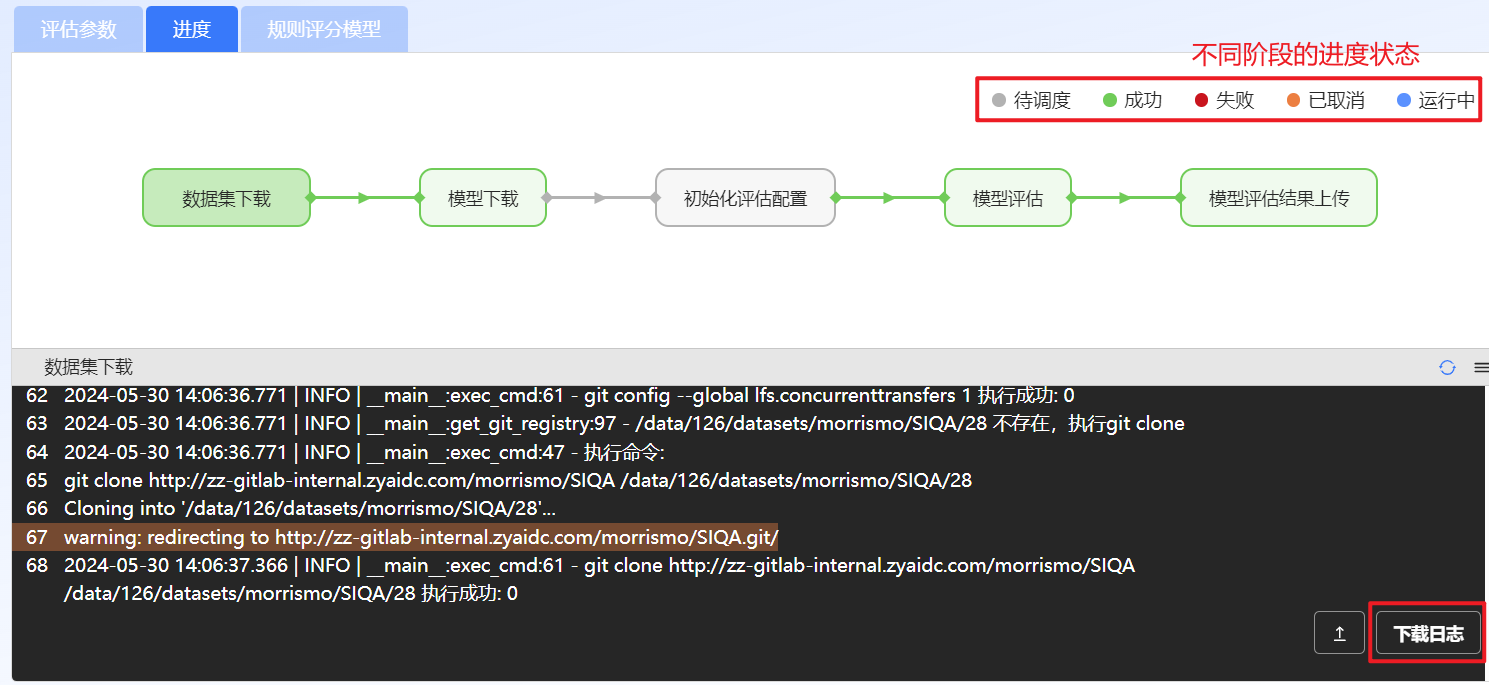
图 68 查看评估进度
在“规则评分模型”页签查看评测结果。
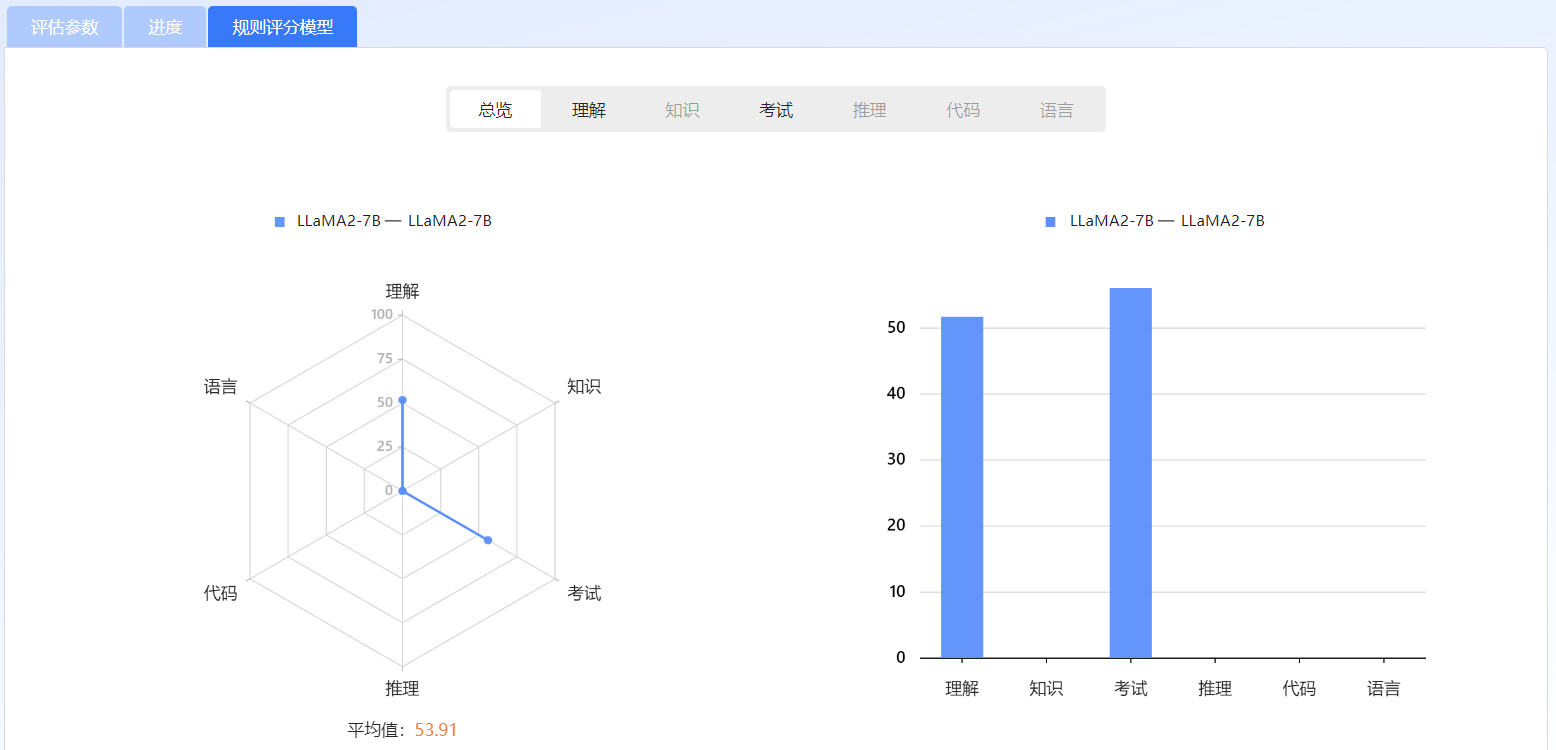
图 69 查看评测结果
模型编译
模型编译包括量化和编译。量化旨在通过量化和稀疏化方法,在尽量减少精度损失的前提下,降低模型的计算和存储需求来提高推理速度和减少资源占用。编译旨在将已训练的模型转换为硬件设备支持的模型权重文件。
登录至VastTrain,在“控制台”页面的左侧导航树选择“模型开发 > 模型编译”,进入“模型编译”页面,包含创建模型编译任务和模型编译任务列表。用户在该页面可创建模型编译任务、导出编译后的模型、部署模型、查看编译详细信息、停止或删除编译任务。模型编译页面如图 70所示。
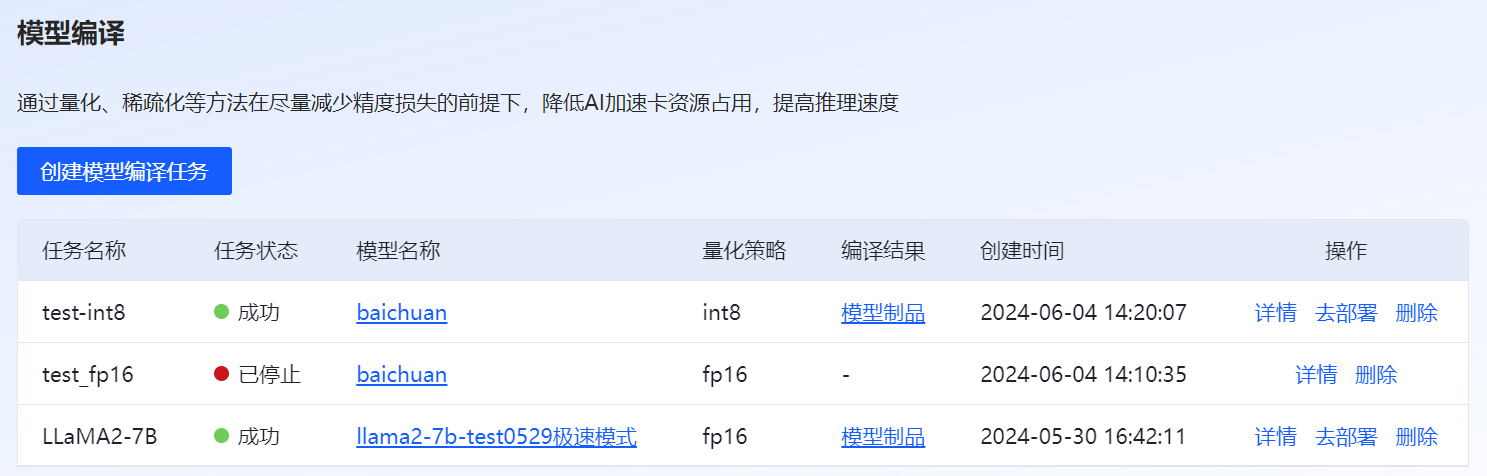
图 70 模型量化编译
创建模型编译任务
创建模型编译任务页面如图 71所示,界面说明如表 15所示。
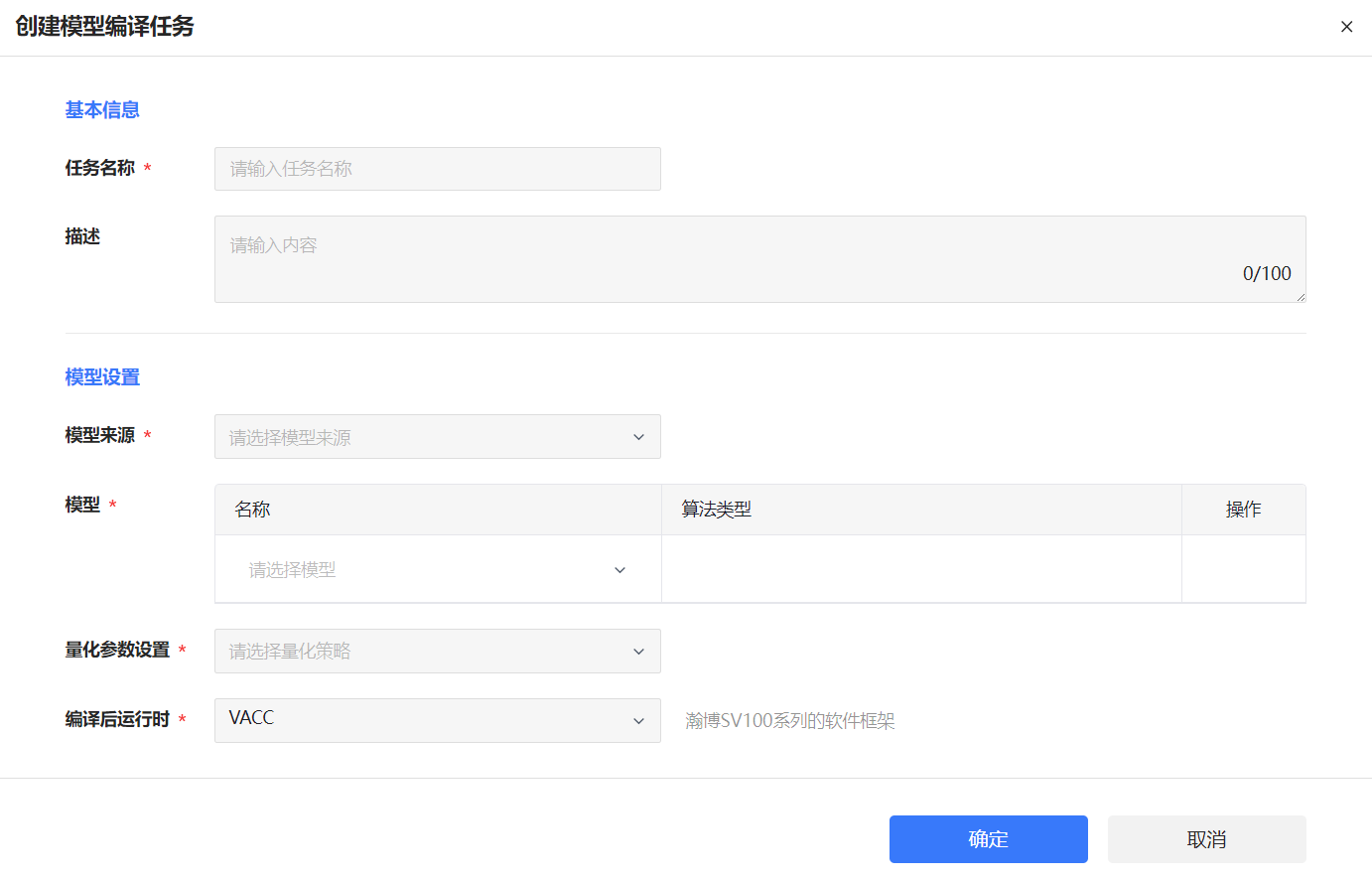
图 71 创建模型编译任务
参数 |
说明 |
|---|---|
任务名称 |
设置模型编译任务名称。 |
描述 |
对模型编译任务进行简单描述。 |
模型来源 |
选择模型来源。支持选择平台内置的模型和用户自己训练的模型。 |
模型 |
选择待量化编译的模型。 |
量化参数设置 |
设置量化参数。支持INT8 和 FP16。 |
编译后运行时 |
选择模型编译后部署的设备。 |
TP值 |
模型部署时Die的数量,当前不支持设置。 |
量化校准数据集 |
设置量化校准数据集。支持C4 和 Ceval。仅量化参数设置为“int8”时需设置。 |
启动编译任务后VastTrain会根据编译时长进行计费,详细可参考计费概述。
查看模型编译详情
在对应的编译任务栏单击“详情”,可查看如下信息。
在“编译参数”页签查看当前编译任务的模型、量化策略等。
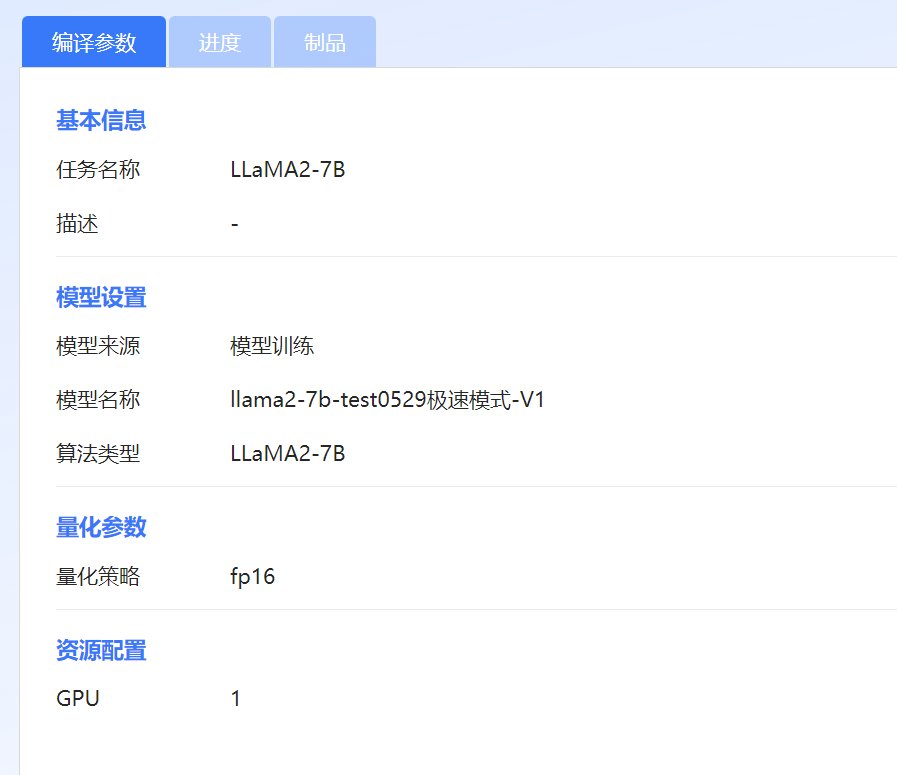
图 72 查看编译参数
在“进度”页签查看量化编译进度以及查看或下载不同阶段的日志信息等。

图 73 查看编译进度
在“制品”页签下载已编译完成的模型。目前仅支持下载单个文件。
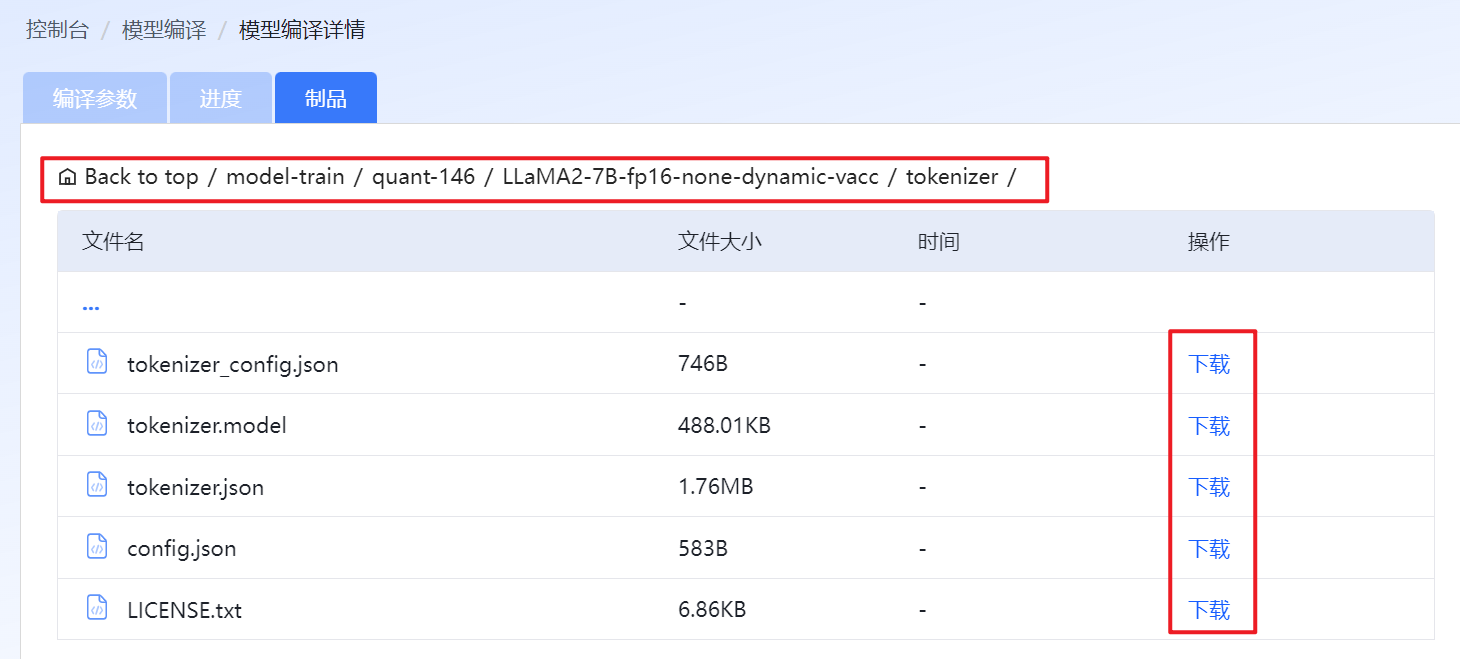
图 74 下载制品