数据工程
数据管理
平台支持统一纳管数据集,并对数据集进行自主版本迭代、继续导入、删除等操作。如果用户当前未准备可用的数据集,也可以选择平台上开源的数据集进行训练、调优、评估操作。
登录至VastTrain,在“控制台”页面的左侧导航树选择“数据工程 > 数据管理”,进入“数据管理”界面。用户可在该页面创建训练数据集,查看所有开源的数据集以及用户自己创建的数据集,也可通过标签筛选或搜索框搜索想要的数据集。此外,用户可通过单击下载数据集,或单击小爱心对数据集进行收藏。数据管理页面如图 28所示。
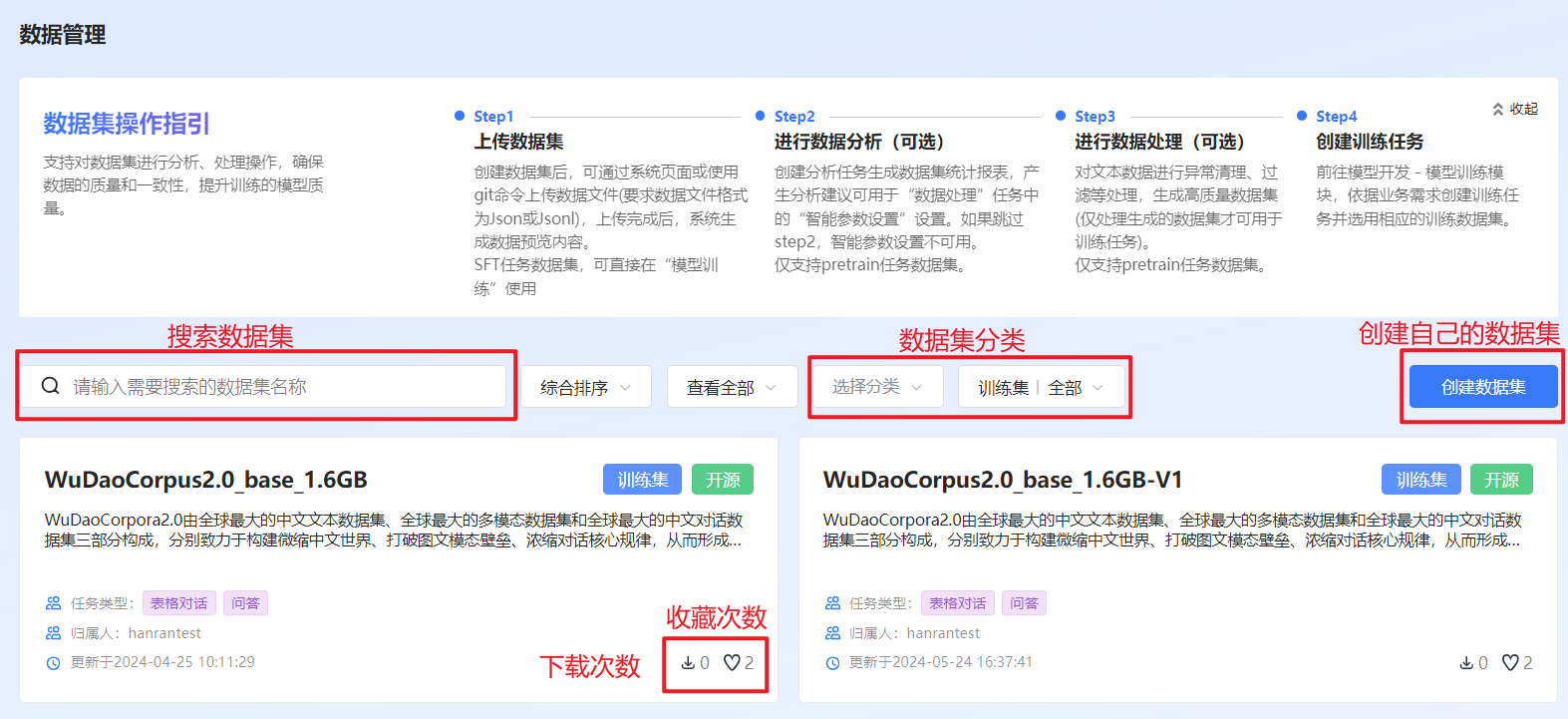
图 28 数据管理
创建数据集
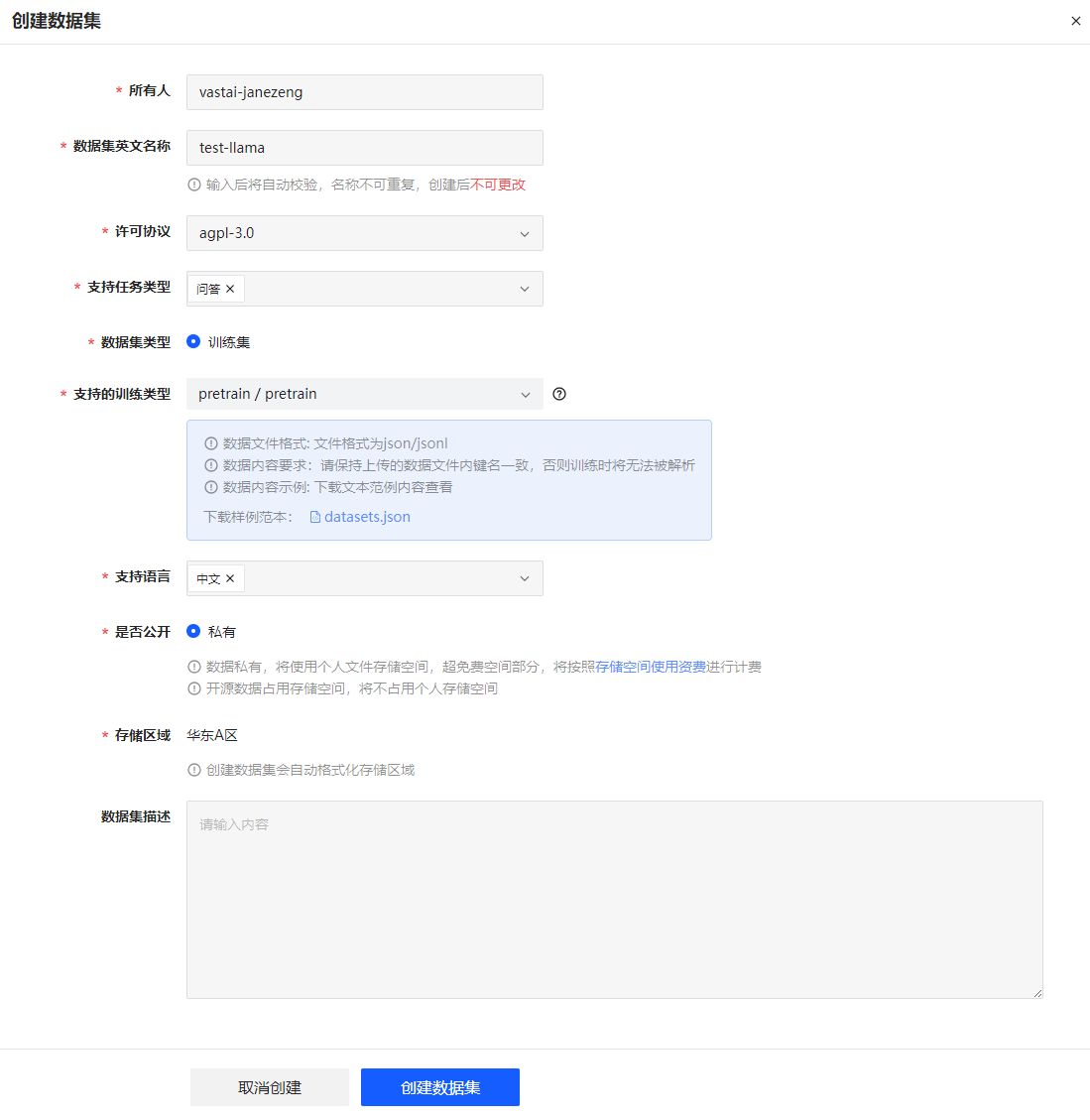
图 29 创建数据集页面
参数 |
说明 |
|---|---|
数据集英文名称 |
输入数据集英文名称。创建后无法修改。 |
许可协议 |
设置数据集License。 |
支持任务类型 |
设置数据集应用类型。如问答、文本分类、翻译等。 |
数据集类型 |
设置数据集类型。 当前仅支持训练集。 |
支持的训练类型 |
设置数据集训练类型。支持 Pretrain、 SFT、DPO。 |
支持语言 |
设置数据集文本语言。 |
是否公开 |
选择数据集是否开源还是私有化 。首次创建时仅支持私有化。
如果数据集私有化,将使用个人文件存储空间,超免费空间部分,将按照存储空间使用资费进行计费。 |
存储区域 |
选择数据集存储区域。当前不支持设置。 |
数据集描述 |
对数据集进行补充描述。 |
数据集创建完成后会在“数据管理”页面显示已创建的数据集,单击创建的数据集,进入数据集详情页面,如图 30所示。
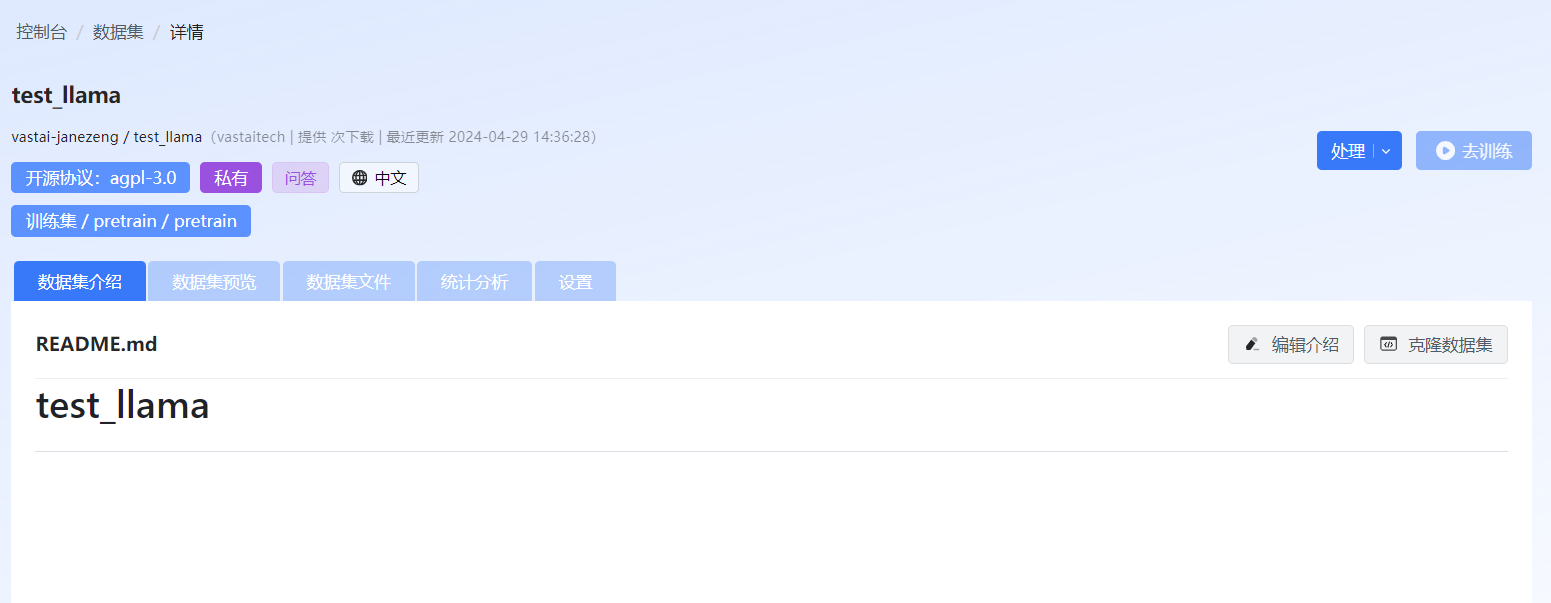
图 30 数据集详情页
在数据集详情页,用户可以进行如下操作。
在“数据集介绍”页签对数据集进行简单的介绍说明,上传数据后支持通过Gitlab克隆已创建的数据集。
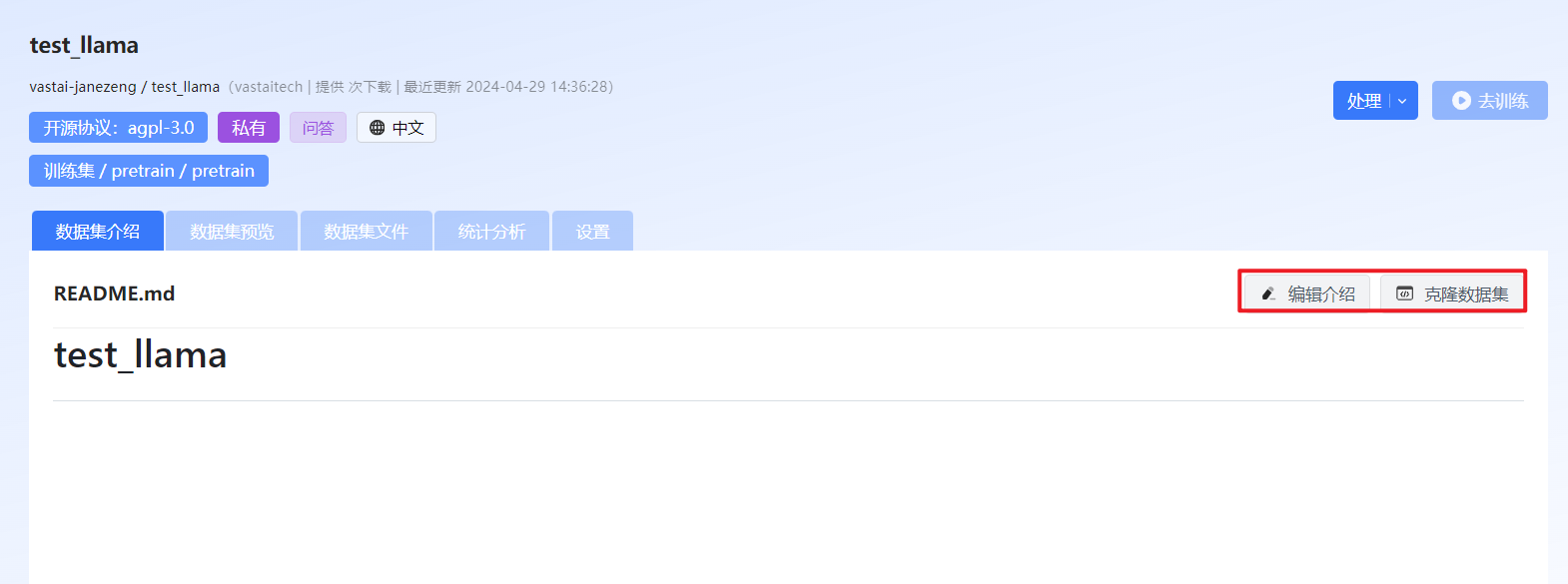
图 31 数据集介绍
针对 SFT 类型的数据集的字段,SFT标准数据集有自己的定义;用户需按照 SFT 标准数据集的结构组装数据,将原始数据集字段映射为标准数据集字段,否则将无法进行训练。
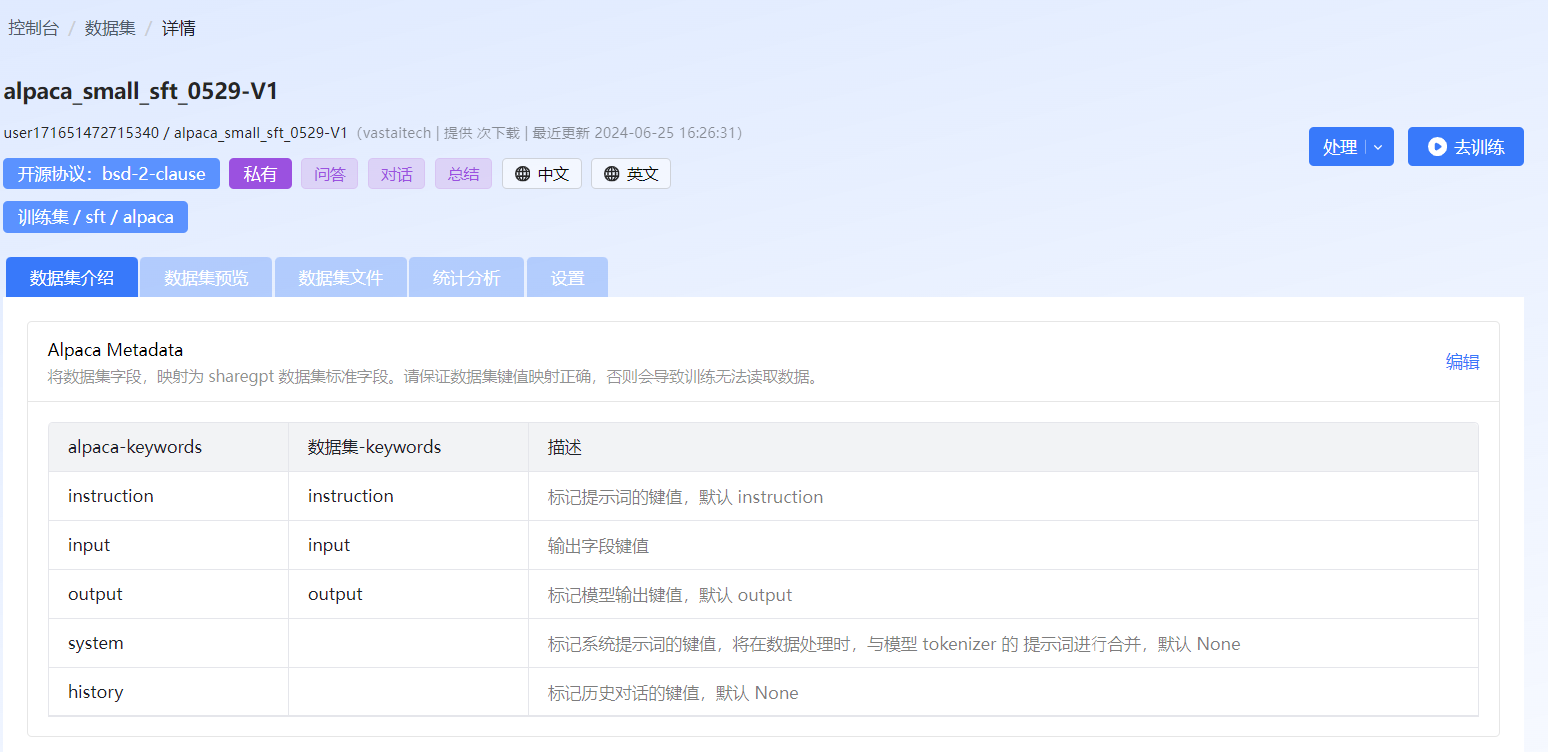
图 32 数据集字段映射
在“数据集预览”页签对添加的数据集进行预览。
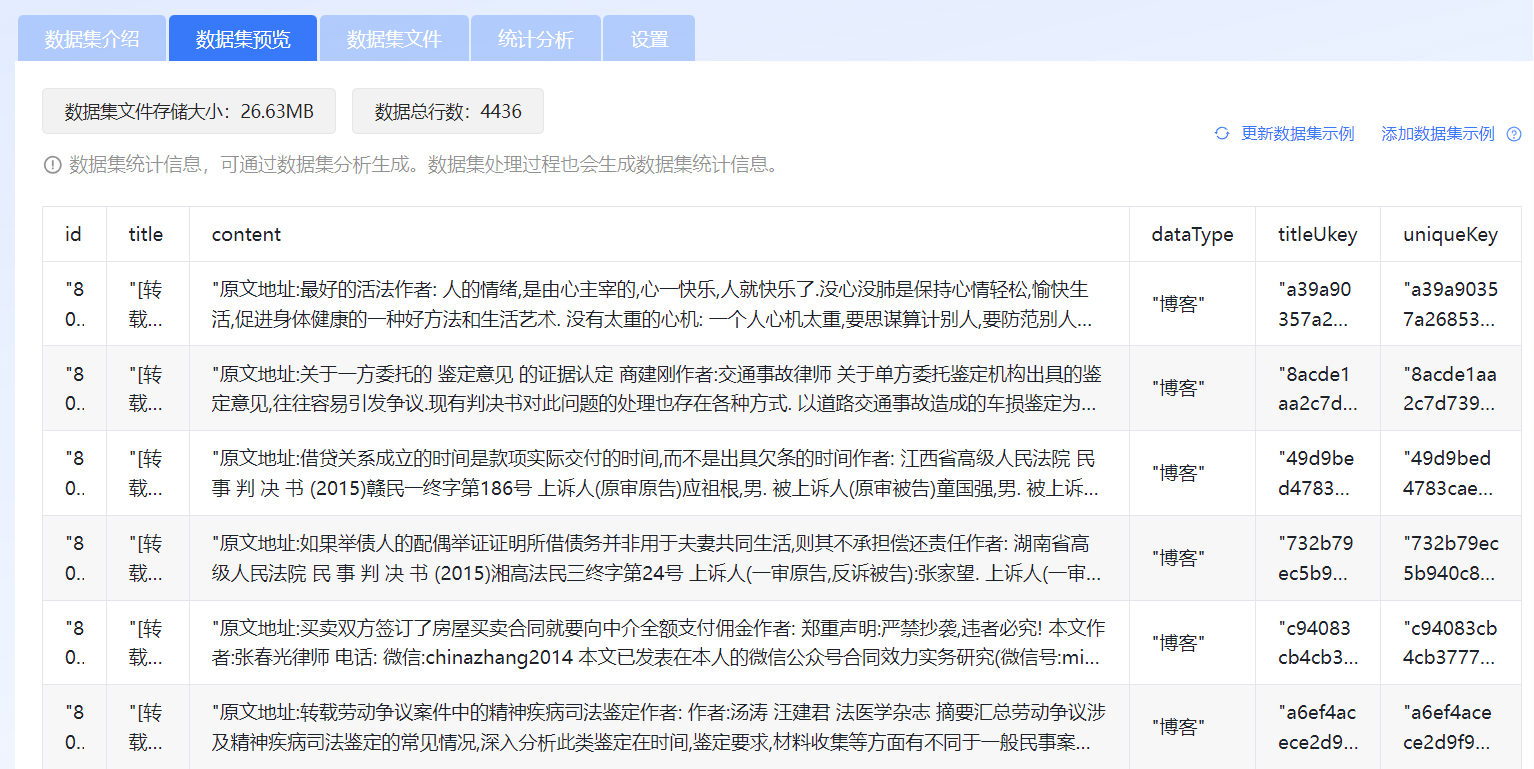
图 33 数据集预览
在“数据集文件”页签上传数据集或下载数据集,支持通过页面直接上传数据集或通过GIT命令上传。
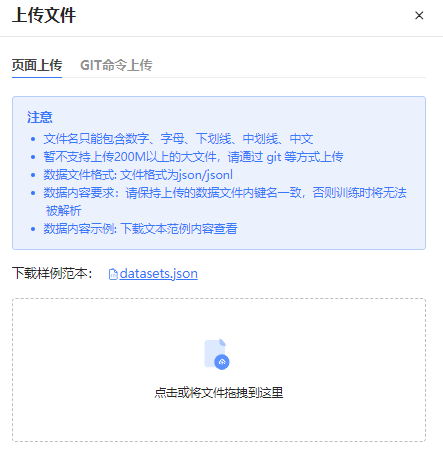
图 34 通过页面上传数据集
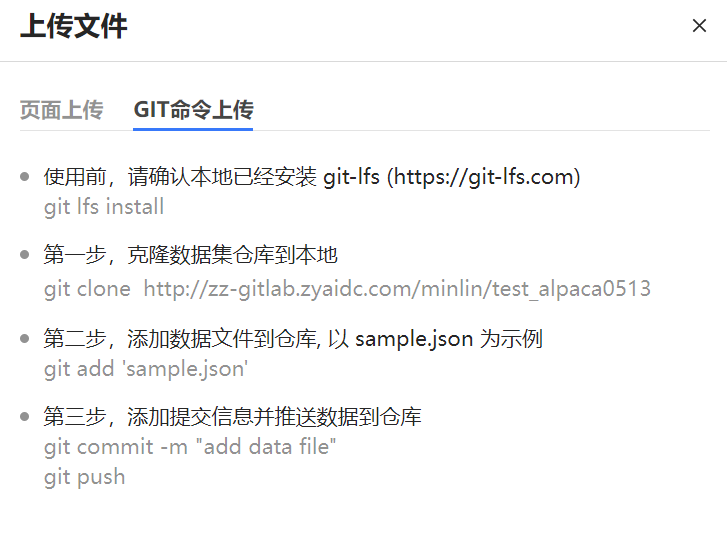
图 35 通过GIT命令上传数据集
在“统计分析”页签对数据集的不同字段进行数据分析,仅训练类型为Pretrain、SFT时支持数据分析。详细说明可参考数据分析。
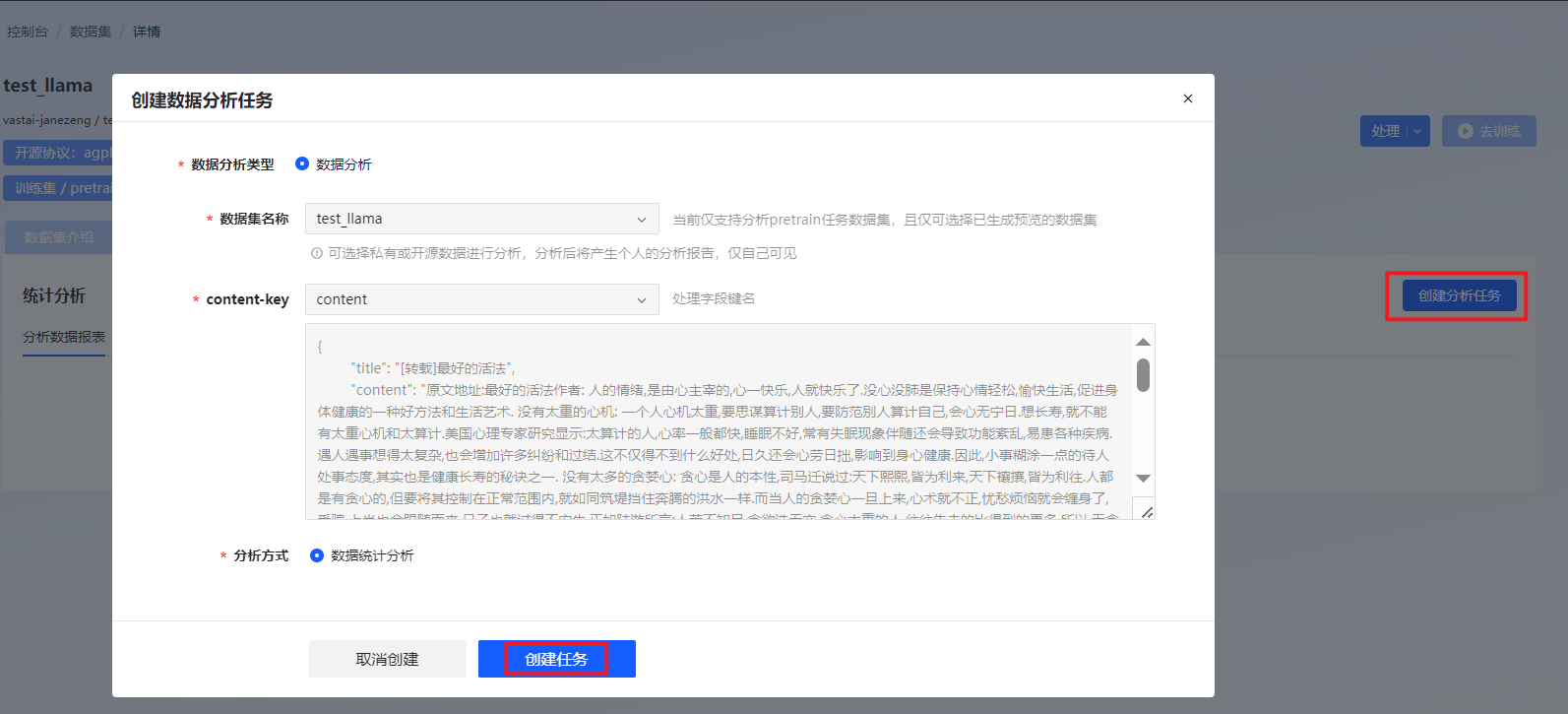
图 36 通过GIT命令上传数据集
在“设置”页签修改数据集基本信息,例如将数据集开源,或删除数据集。
针对Pretrain训练数据集(训练类型为Pretrain),上传数据后需经过数据分析处理后的数据集才能开源。
针对SFT训练数据集(训练类型为SFT),上传数据后无需经过数据处理即可开源。
针对DPO训练数据集(训练类型为DPO),上传数据后无需经过数据处理即可开源。
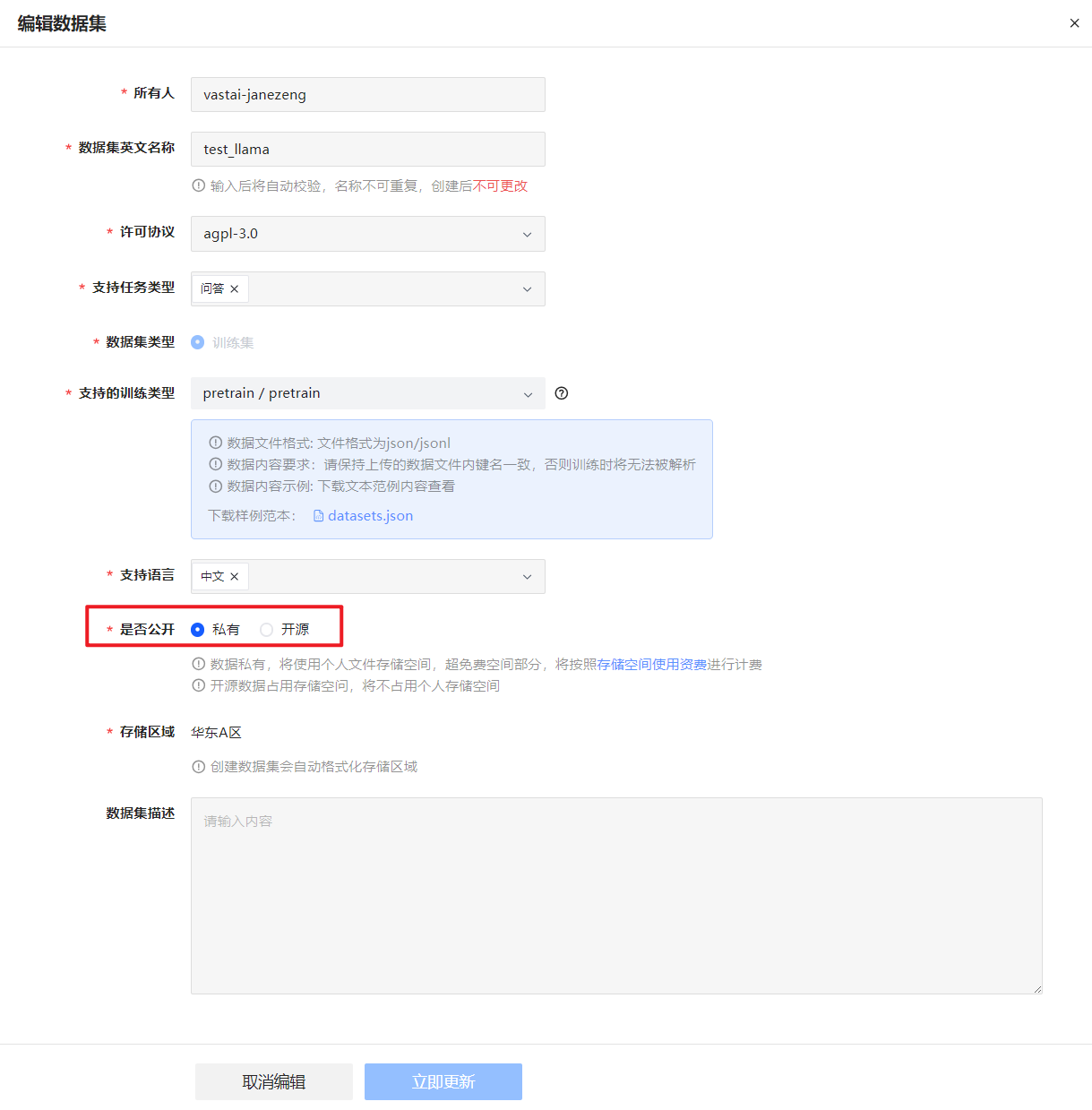
图 37 修改数据集基本信息
数据分析
数据分析用于对数据集进行特征值统计分析,指示数据分布情况并给出数据处理建议,指导用户在“数据处理”任务中如何设置过滤算子,帮助用户更好的理解数据,为模型训练提供更准确的基础数据。当前仅支持训练类型为“Pretrain”和“SFT”的训练数据集进行数据分析。
登录至VastTrain,在“控制台”页面的左侧导航树选择“数据工程 > 数据分析”,进入“数据分析”页面,包含创建分析任务和分析任务列表。用户在该页面可创建分析任务、查看分析统计结果、查看分析不同阶段的日志信息、停止或删除分析任务。数据分析页面如图 38所示。

图 38 数据分析
创建分析任务
创建分析任务页面如图 39所示,界面说明如表 2所示。用户也可直接在数据集的“详情 > 统计分析”页面创建分析任务。
备注
待数据集自动生成预览后才能创建分析任务。
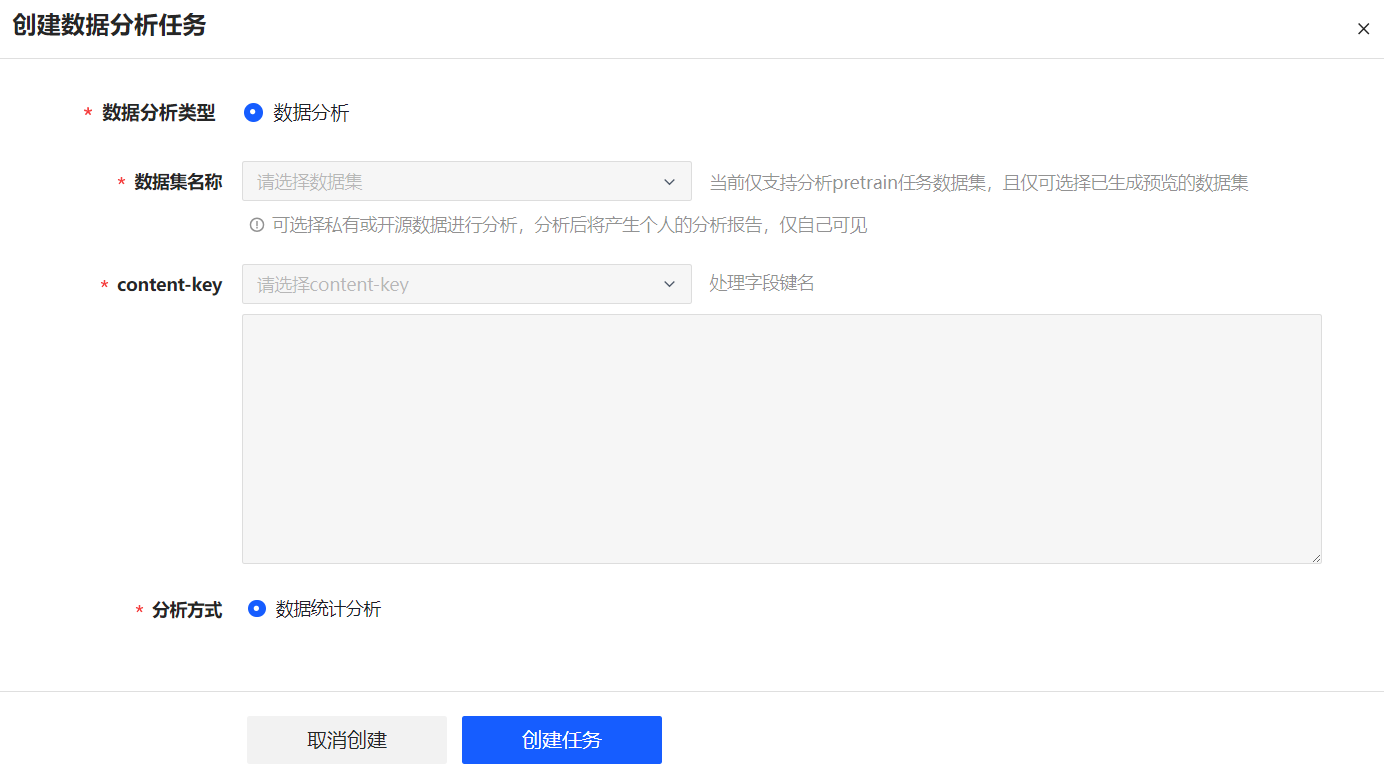
图 39 创建数据分析任务
参数 |
说明 |
|---|---|
数据分析类型 |
选择数据分析类型。当前不支持设置。 |
数据集类型 |
选择数据集类型。支持 Pretrain 和 SFT 数据集。 |
数据集名称 |
选择待分析的数据集。当前仅支持训练类型为“Pretrain”和“SFT”的训练数据集。已分析的数据集不支持二次分析。 |
content-key/meta-data |
选择数据集中的字段进行分析。 待分析的数据集为 “Pretrain” 类型时界面显示“content-key”。待分析的数据集为 “SFT” 类型时,界面显示“meta-data”。 |
分析方式 |
选择数据分析方式。当前不支持设置。 |
资源池 |
可设置为高速或极速。
|
查看分析任务
待数据分析完成后,用户可进行如下操作。
在对应的分析任务栏单击“分析统计”查看分析统计结果,包括分析数据报表、分析统计图表以及数据处理建议。
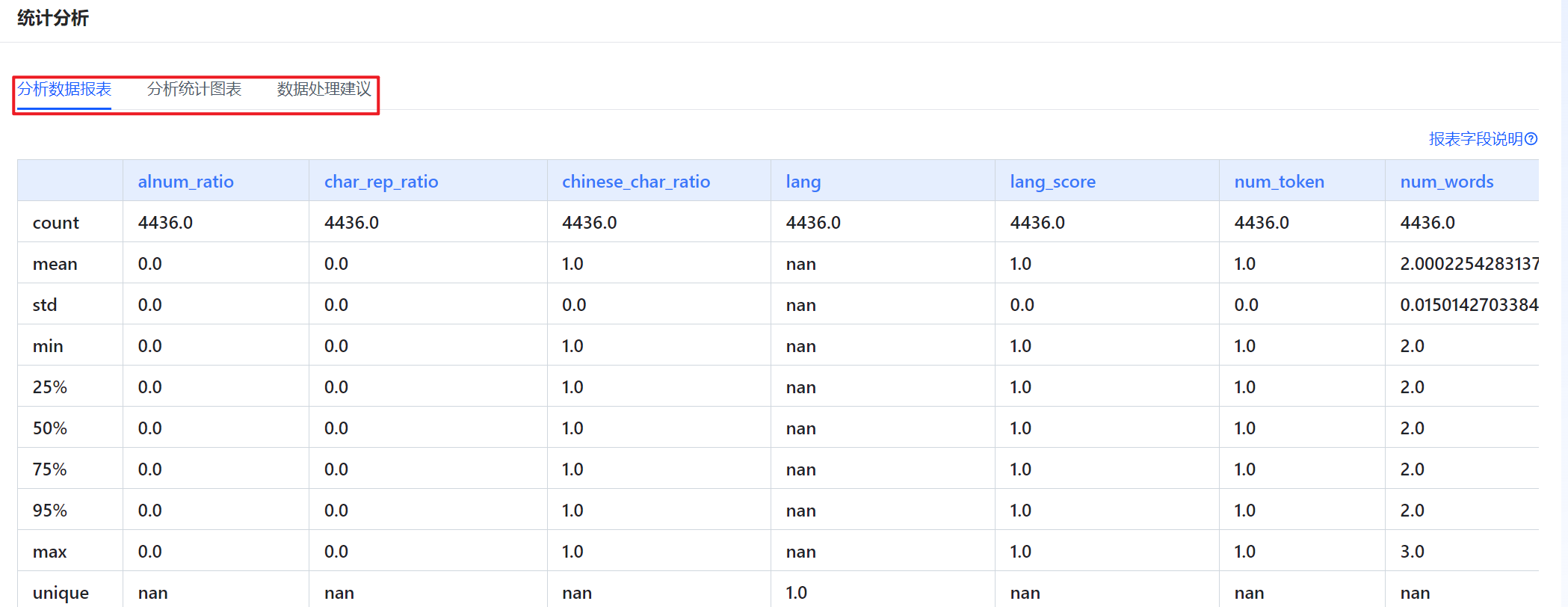
图 40 分析统计结果
在对应的分析任务栏单击“详情”查看并下载分析任务不同阶段的运行日志。
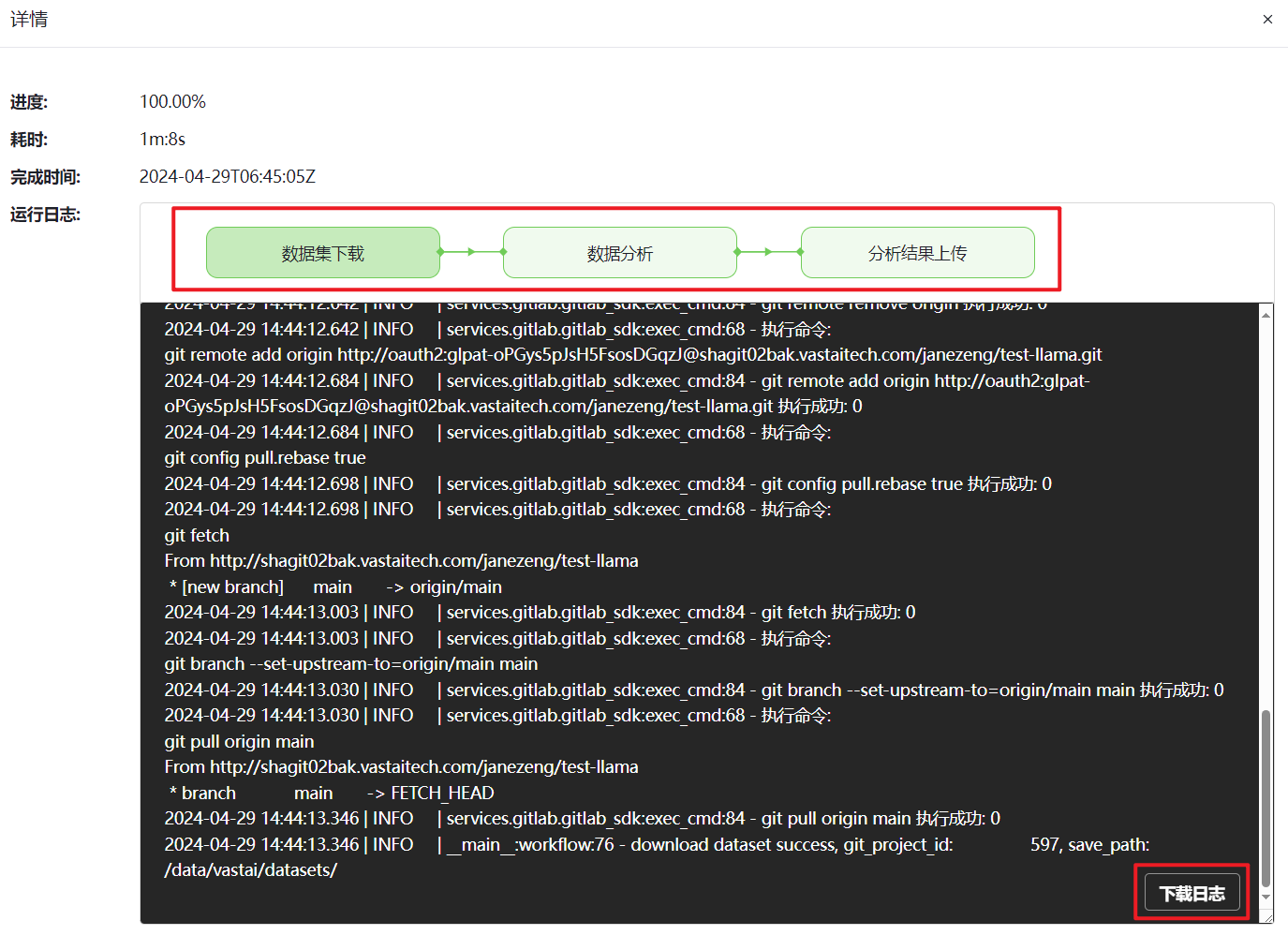
图 41 查看日志信息
数据处理
数据处理是专注于Pretrain训练场景下范文本数据的全方位数据处理解决方案,包括数据清洗、文本过滤、文本去重、隐私信息移除以及数据增强,以提高数据质量,从而提升模型的训练效果。当前仅支持训练类型为“Pretrain” 和“SFT”的训练数据集进行数据处理。
登录至VastTrain,在“控制台”页面的左侧导航树选择“数据工程 > 数据处理”,进入“数据处理”页面,包含创建处理任务和处理任务列表。用户在该页面可创建处理任务、查看数据处理不同阶段的日志信息、停止或删除处理任务等操作。数据处理页面如图 42所示。
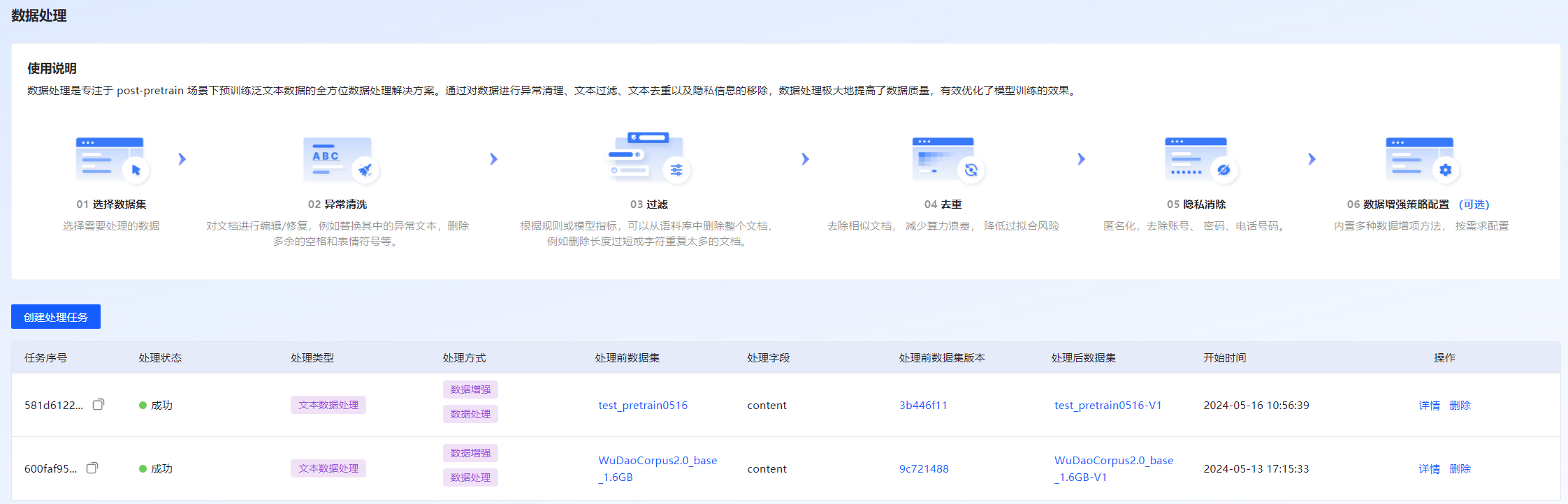
图 42 数据处理
创建处理任务
创建处理任务页面如图 43所示,包括基本信息、异常清洗、过滤、去重、隐私保护、数据增强。详细说明如下所示。
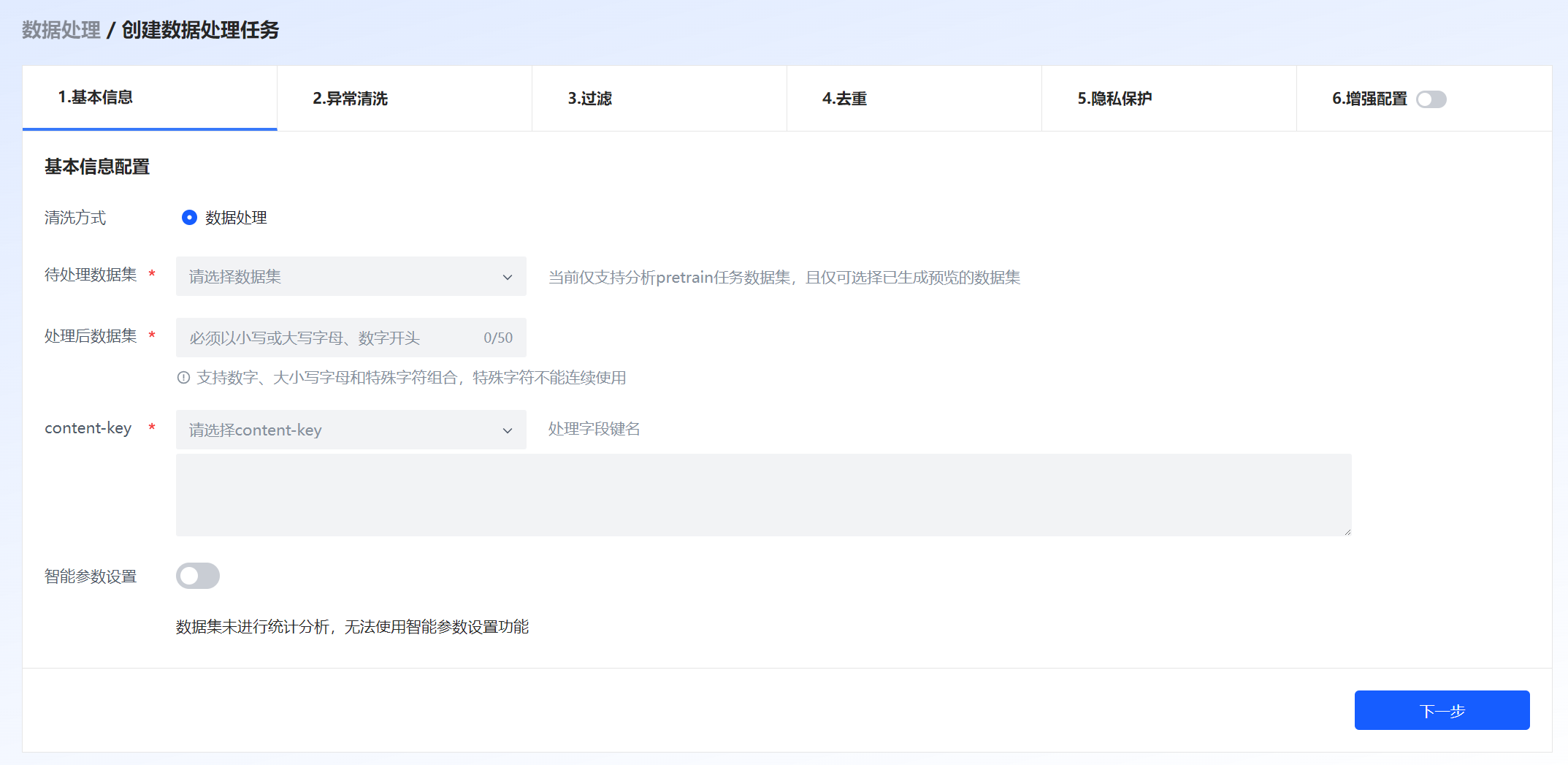
图 43 创建数据处理任务
参数 |
说明 |
|---|---|
清洗方式 |
选择清洗方式。当前不支持设置。 |
数据集类型 |
选择数据集类型。支持 Pretrain 和 SFT 数据集。 |
待处理数据集 |
选择待处理的数据集。 |
处理后数据集 |
设置处理后的数据集名称。 支持数字、大小写字母和特殊字符组合,特殊字符不能连续使用。 |
content-key/meta-data |
选择数据集中的字段进行处理。 待处理的数据集为 “Pretrain” 类型时界面显示“content-key”。待处理的数据集为 “SFT” 类型时,界面显示“meta-data”。 |
智能参数设置 |
是否开启智能参数设置。仅数据进行分析后才支持开启。开启后,针对数据过滤类型算子,平台根据数据分析结果自动设置最优参数值。 |
资源池 |
可设置为高速或极速。
|
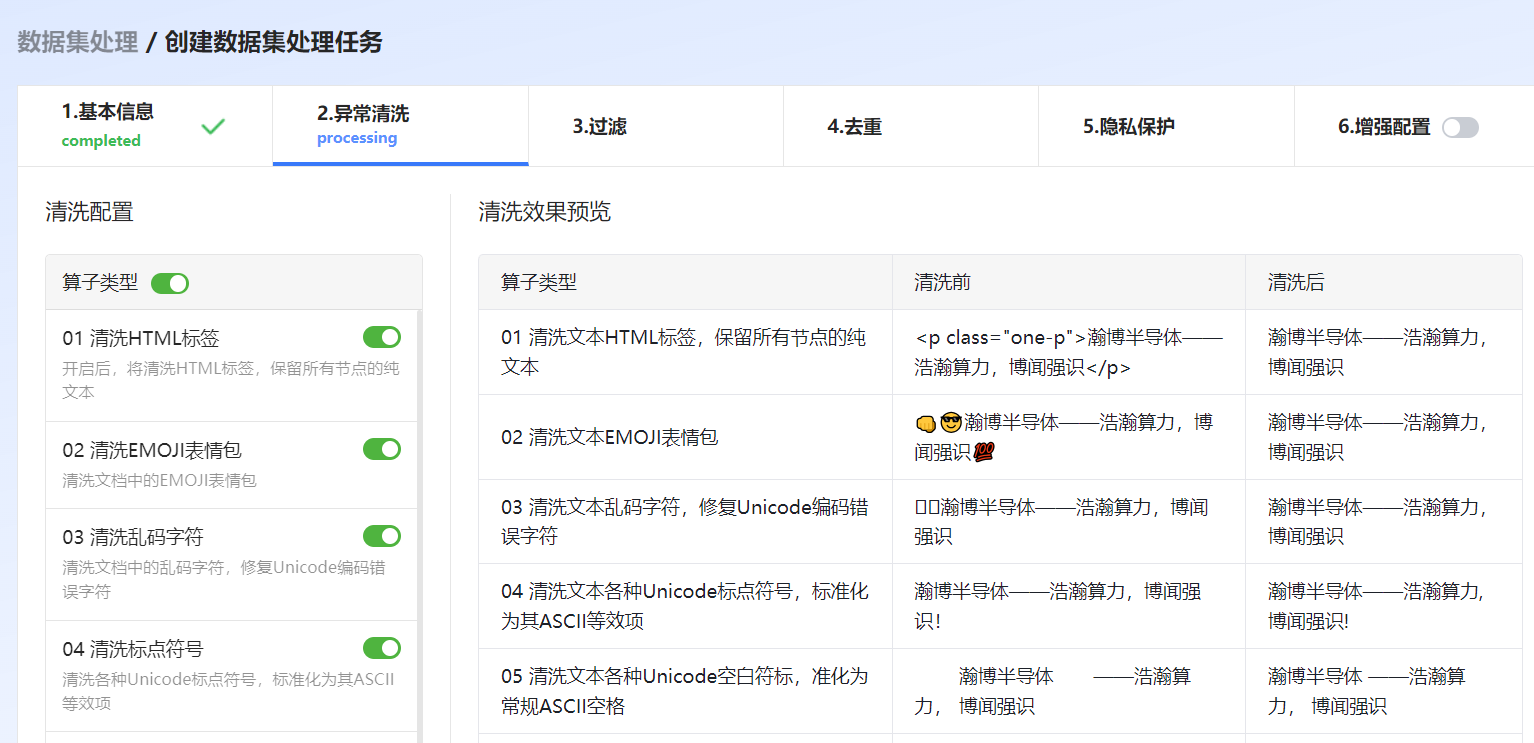
图 44 异常清洗
算子类型 |
说明 |
|---|---|
清洗HTML标签 |
清洗HTML标签,保留所有标签内的纯文本。 |
清洗EMOJI表情包 |
清洗文本中EMOJI表情包。 |
清洗乱码字符 |
清洗文本中的乱码字符,修复Unicode编码错误字符。 |
清洗标点符号 |
将Unicode格式的标点符号转换为ASCII格式。 |
清洗空白符 |
将Unicode格式的空格转换为ASCII格式。 |
清洗冗余字符串 |
清洗文本中冗余的中文字符串(大于三个重复字符)。 |
清洗全角字符 |
将全角字符转换为半角字符。 |
清洗大写字符 |
将大写字符转换为小写字符。 |
清洗特殊符号 |
清洗文本中特殊符号。 |
清洗非中文字符 |
清洗文本中非中文字符,支持选择是否保留数字、字母或标点符号。 |
清洗文档中长度超出指定范围的行 |
设置“文本上限长度”后,清洗文本中超出“文本上限长度”的内容。 |
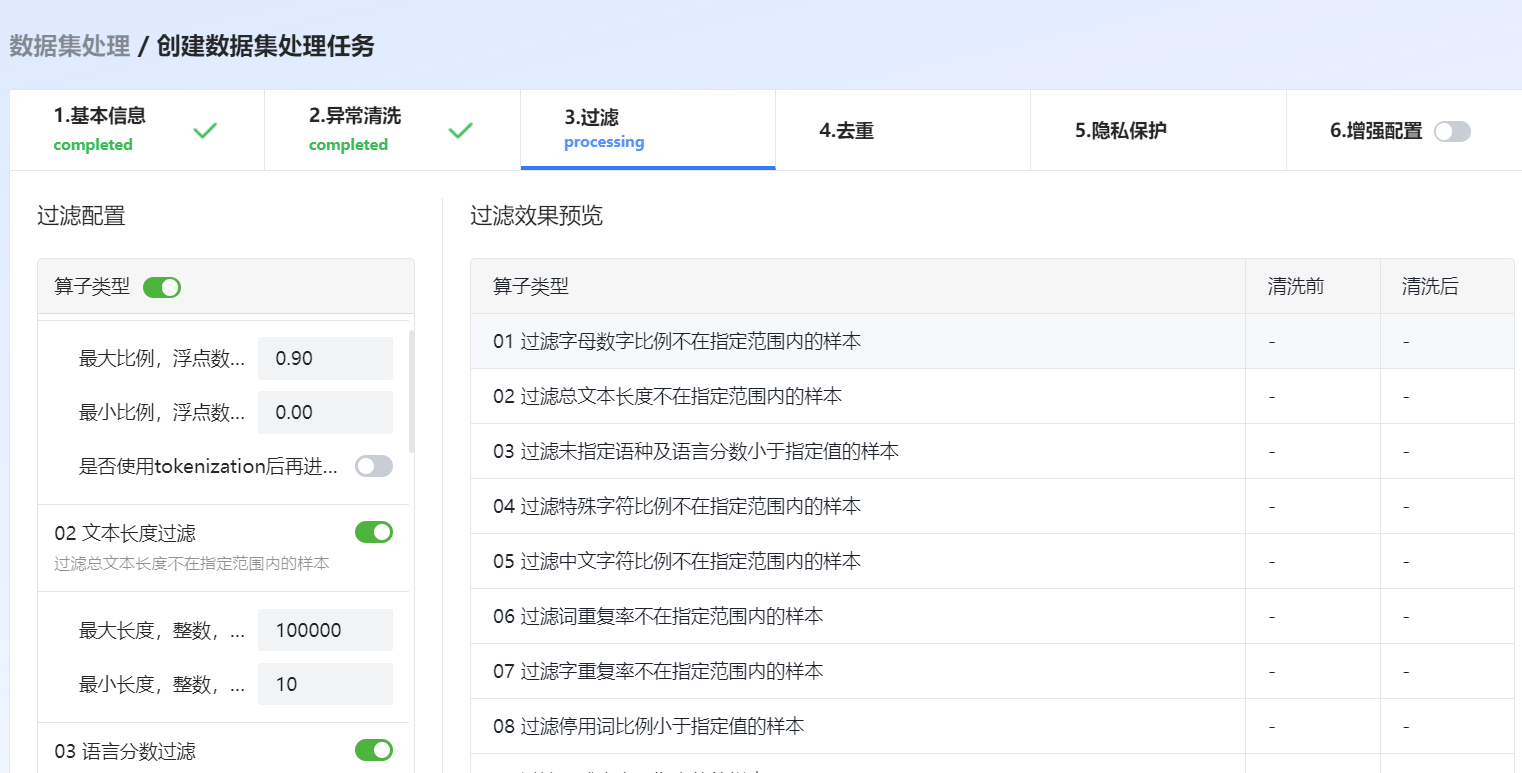
图 45 过滤
算子类型 |
说明 |
|---|---|
字母数字比例过滤 |
过滤掉大于最大字母数字比例的文本和小于最小字母数字比例的文本。支持分词后再进行过滤。 |
文本长度过滤 |
过滤掉大于最大总文本长度的文本和小于最小总文本长度的文本。 |
语言分数过滤 |
过滤掉未指定语种的文本和小于语言分数的文本。 |
特殊字符比例过滤 |
过滤掉大于最大特殊字符比例的文本和小于最小特殊字符比例的文本。 |
中文字符比例过滤 |
过滤掉大于最大中文字符比例的文本和小于最小中文字符比例的文本。 |
词重复率过滤 |
过滤掉大于重复长度的文本、大于最大词重复率的文本和小于最小词重复率的文本。 |
字重复率过滤 |
过滤掉大于重复长度的文本、大于最大字重复率的文本和小于最小字重复率的文本。支持分词后再进行过滤。如果语言分数过过滤算子中指定了保留的语种,则该算子中“文本语种”参数无效。 |
停用词过滤 |
过滤小于最小停用词比例的文本。支持分词后再进行过滤 。如果语言分数过过滤算子中指定了保留的语种,则该算子中“文本语种”参数无效。 |
困惑度过滤 |
过滤掉大于最大困惑度的文本。 如果语言分数过过滤算子中指定了保留的语种,则该算子中“文本语种”参数无效。 |
字数过滤 |
过滤掉大于最大字数长度的文本和小于最小字数长度的文本。 支持分词后再进行过滤 。如果语言分数过过滤算子中指定了保留的语种,则该算子中“文本语种”参数无效。 |
token数过滤 |
过滤掉大于最大Token数的文本和小于最小Token数的文本。 支持选择Hugging Face框架的模型,同时支持选择是否使用本地模型进行Token数过滤。 |
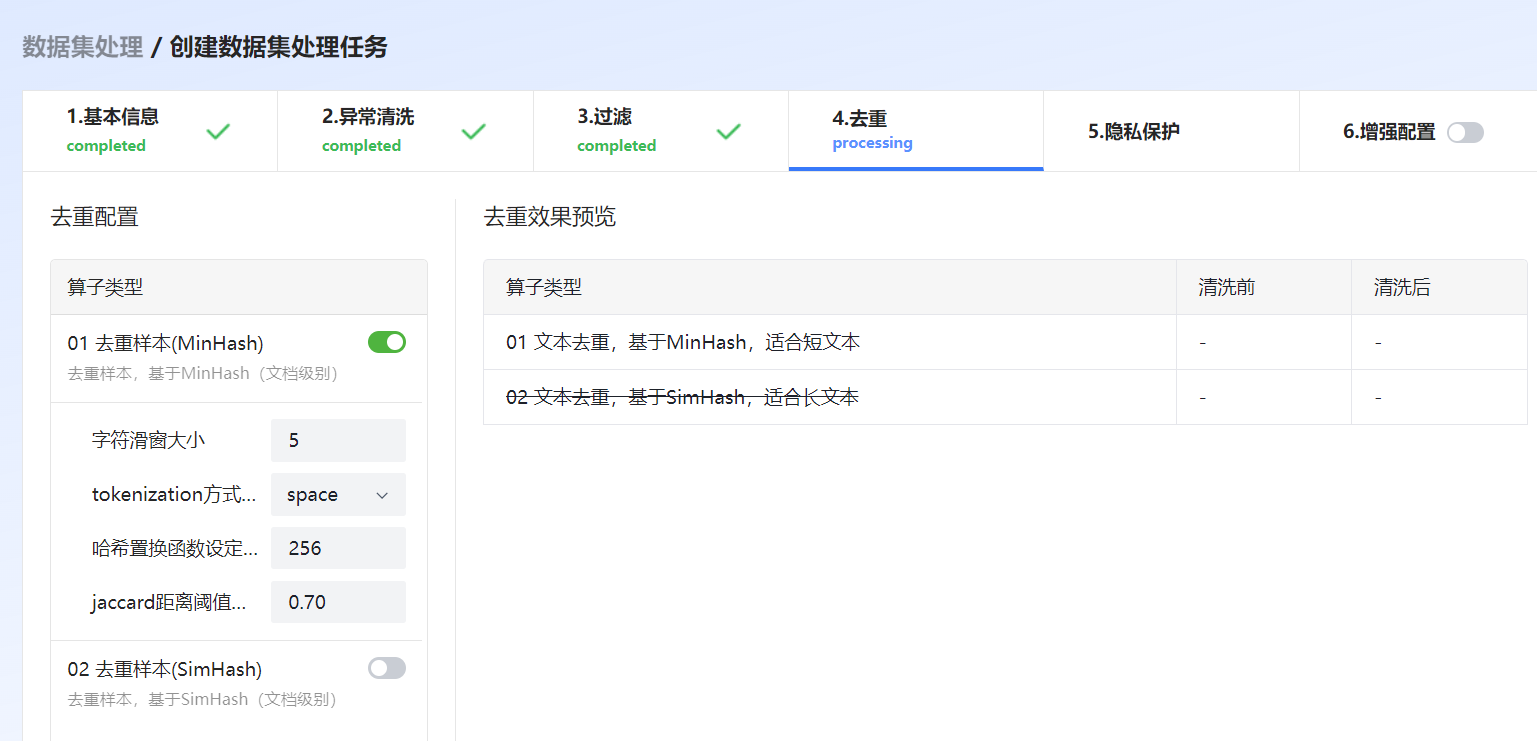
图 46 去重
参数 |
说明 |
|---|---|
去重样本(MinHash) |
基于MinHashLSH(文档级别)去重文本,适用于短文本。
|
去重样本(SimHash) |
基于SimHash(文档级别)去重文本,适用于长文本。
|
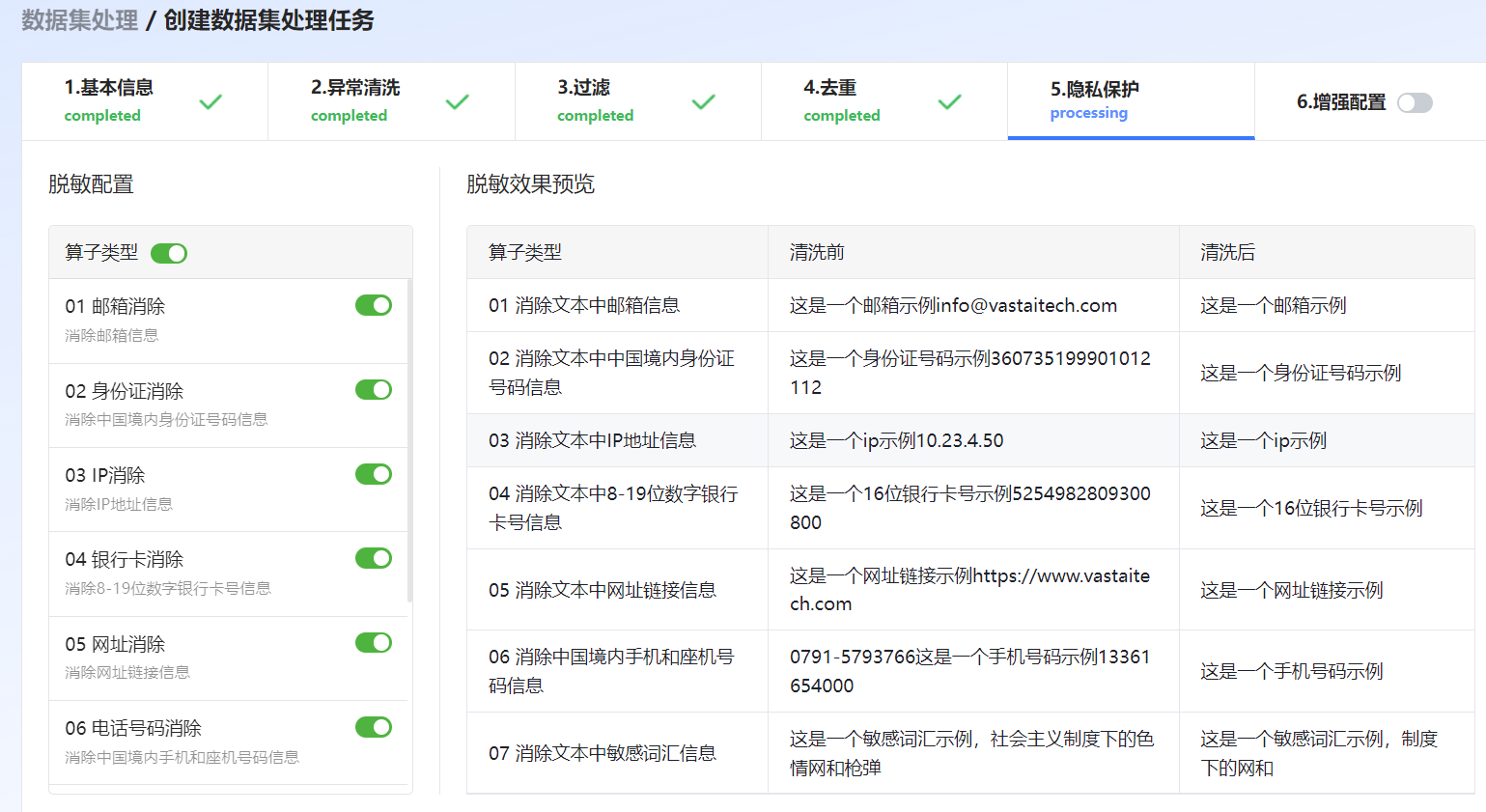
图 47 隐私保护
算子类型 |
说明 |
|---|---|
邮箱消除 |
消除文本中邮箱信息。 |
身份证消除 |
消除文本中中国境内身份证号码信息。 |
IP消除 |
消除文本中IP地址信息。 |
银行卡消除 |
消除文本中8~19位银行卡号信息。 |
网址消除 |
消除文本中网址链接信息。 |
电话号码消除 |
消除中国境内手机和座机号码信息。 |
敏感词汇消除 |
消除文本中敏感词汇信息 。支持设置敏感词汇替换字符,支持消除涉政词汇、暴乱暴恐词汇、色情词汇。 |
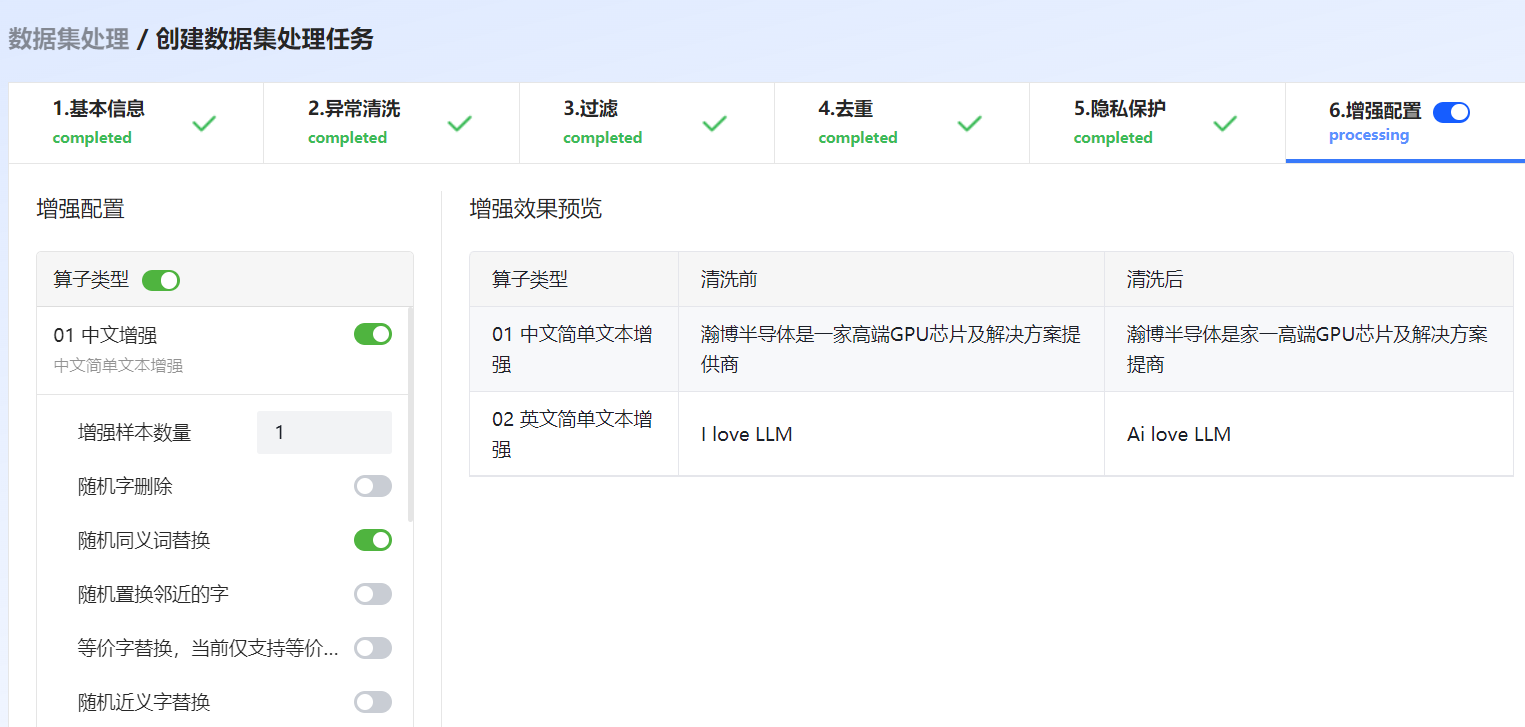
图 48 隐私保护
算子类型 |
说明 |
|---|---|
中文增强 |
中文增强,支持设置增强的样本数量、随机字删除、同义词替换、随机置换邻近字、近义字替换、数字等价字替换。 |
英文增强 |
英文增强,支持设置增强的样本数量、OCR字符识别错误、随机置换邻近字符、随机置换邻近单词、随机拆分单词、随机删除字符、随机删除单词、随机插入字符、键盘字符错误、拼写单词错误。 |
查看数据处理任务
待数据处理完成后,用户可进行如下操作。
在对应的数据处理任务栏单击“详情”查看并下载分析任务不同阶段的运行日志。
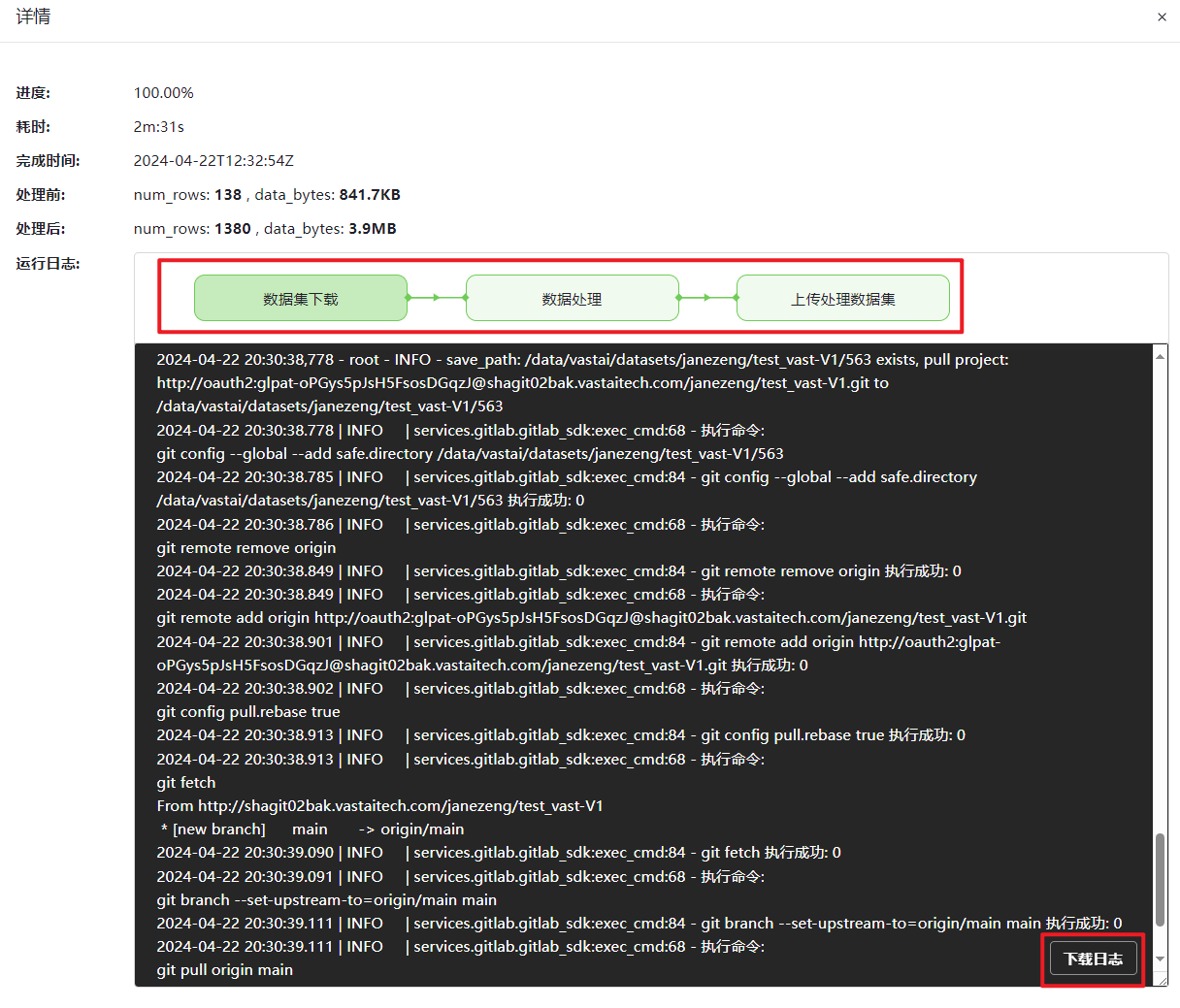
图 49 查看日志信息